
Zaintrygowany ostatnim artykułem Roberta nt. porównania dostępnych dróg dostarczania plików na Kindle postanowiłem napisać ten artykuł, aby wyjaśnić kilka technicznych niejasności i pokazać jak skonfigurować Calibre. W efekcie będziemy mogli skorzystać ze wszystkich dobrodziejstw nowych modeli naszych ulubionych e-czytników.
13.10.14 – Artykuł został zaktualizowany. Opisywane metody zostały ponownie sprawdzone przy użyciu Calibre 2.5 z pluginami Hypernate This! 0.0.8 i Quality Check 1.9.11.
Trochę teorii
Na początek zaznaczam, że jestem osobą, która dostarcza pliki jedynie przez kabel USB. Metoda wysyłania ich przez e-mail jest dla mnie nieoptymalna, jako że użytkownik nie posiada żadnej kontroli nad procesem konwersji, której dokonuje machineria Amazonu.
Nim przejdziemy do samej konfiguracji Calibre – kilka spraw technicznych i definicji.
Mamy obecnie dwa główne formaty e-książek, które są obsługiwane przez nowe modele Kindle. Ich nazwy są często mylone, więc postaram się raz na zawsze rozwiać wątpliwości w tym temacie.
- MOBI7 – Stary format
- KF8 – Nowy format
Nie było by w tym nic skomplikowanego gdyby nie fakt, że mówię tutaj o formacie, a nie rozszerzeniu pliku.
Jeżeli chodzi o rozszerzenie pliku to na dzień dzisiejszy najczęściej spotykamy się z:
- MOBI
- AZW
- AZW3
- EPUB
Celowo pomijam PDFy. Osobiście uważam, że kwalifikowanie ich, jako formatu godnego e-książki to całkowita pomyłka.
Odłóżmy również na chwilę EPUBy. Jak dobrze wiemy by otworzyć je na Kindle (bez modyfikacji oprogramowania) musimy je najpierw przekonwertować to MOBI bądź AZW/AZW3.
I teraz zaczynają się schody. Problem, który powoduje najwięcej zamieszania. Jakie związek jest miedzy formatem, a rozszerzeniem e-książki?
W wypadku pliku AZW/.AZW3 sprawa jest prosta. Może być on jedynie w formacie KF8. Gdy mamy w ręku plik AZW/AZW3 jesteśmy pewni, co znajduje się w środku.
Jednak, gdy mamy plik MOBI sprawa się komplikuje. W środku może znajdować się plik:
- MOBI7
- KF8
- MOBI7+KF8 – Tak. Oba na raz.
Gdy mamy już tą wiedzę, mogę wyjaśnić, co chcę dzisiaj osiągnąć.
- Chcę zapomnieć o plikach MOBI i formacie MOBI7.
- Chcę używać jedynie plików AZW3 w formacie KF8.
- Chcę by wszystkie książki, niezależnie czy przekonwertowane samemu, czy kupione poza ekosystemem Amazonu nie posiadały oznaczenia Personal i miały okładkę.
Konfiguracja Calibre
Osiągniecie powyższych celów jest bajecznie proste. Musimy jedynie wykonać jedynie kilka zmian w konfiguracji Calibre.
Zaczynamy od zmian w Opcjach wspólnych.

Jeżeli planujemy używać pluginu Hyphenate This! (Co gorąco polecam!) uruchamiamy zakładkę Wygląd i zachowanie by wymusić wyjustowanie tekstu. Opcje Wyrównanie tekstu ustawiamy na Wyjustowanie tekstu. O samym pluginie pisał wcześniej Robert.
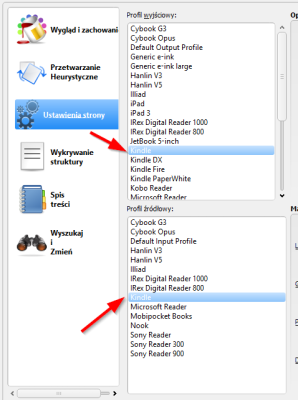
Później interesuje nas tam zakładka Ustawienia strony. Profil wejściowy ustawiamy na Kindle. Profil wyjściowy ustawiamy na nasz model.
Osobiście polecam również zajrzeć do zakładki Przetwarzanie Heurystyczne i zaznaczyć tam wszystkie opcje. Zdecydowanie wydłuża to czas konwersji ale w większości przypadków podnosi jakość formatowania książki.
Zastosowujemy zmiany i przechodzimy do Opcji wyjścia. Wybieramy Wyjściowy AZW3.
O ile nie potrzebujemy udostępniać zawartości książki na Facebooku itp. to odznaczamy wszystkie opcje. W przeciwnym wypadku zaznaczamy jedynie opcję ostatnią.

Uwaga! Włączenie tej opcji uniemożliwia synchronizacje informacji o ostatnio przeczytanej stronie gdy używamy wielu urządzeń.
Zapisujemy zmiany. Zamykamy opcje i podłączamy naszego Kindle do komputera. Gdy Calibre go wykryje pojawi nam się dodatkowa ikona w pasku.

Uruchamiamy Konfiguruj urządzenie i ustawiamy je w następujący sposób:
(Przy czym Używaj podkatalogów jest opcjonalne)

Co nam to da? Spieszę z odpowiedzią. Kindle od tego momentu będzie przyjmował tylko pliki AZW3 i MOBI. Wszystko, co nie jest AZW3/MOBI zostanie konwertowane do AZW3. Dlaczego ciągle przyjmujemy MOBI mimo tego, że chcemy się z nim rozstać? Bardzo dobre pytanie. Odpowiedź jest prosta – książki niestworzone przez nas. Konwersja na siłę do formatu AZW3 może po prostu zniszczyć ich formatowanie. Więc chcemy je używać w formie stworzonej przez autora – bez żadnych modyfikacji.
Np. piki MOBI z komiksami stworzone przez Kindle Comic Converter nie mogą być konwertowane do formatu AZW3. Konwerter Calibre najzwyczajniej w świecie je uszkadza.
Jeżeli ktoś chce się katować fatalnym wsparciem formatu PDF to musimy go tutaj też zaznaczyć i przesunąć pod MOBI.
Dodatkowo Kindle znacznie dokładniej będzie obliczał ilość stron w dokumentach.
Tyle. Konfiguracja zakończona. Nim jednak rozpoczniemy konwersje naszych plików MOBI/EPUB do AZW3 musimy pamiętać by dodać okładkę do rekordu książki. Gdyż domyślnie w czasie konwersji masowej Calibre używa okładki z własnej bazy a nie z samego pliku.
Nim wgramy na czytnik nasz świeżo skonwertowany plik polecam potraktować go pluginem Hyphenate This!.
Naprawa plików MOBI dostarczanych przez innych
Gdy Calibre wykona konwersje pliku do AZW3 to problemu nie ma, ale gdy dostaliśmy już gotowy plik MOBI np. z e-księgarni i nie chcemy go konwertować to tag Personal może się w tym przypadku pojawić.
Niektóre książki Calibre będzie w stanie sam skorygować. Ale czasami mu się to nie uda. Gdy po wgraniu książki widzimy tag Personal to musimy delikatnie zmodyfikować plik MOBI przy pomocy mniej inwazyjnych metod niż pełna konwersja pliku.
Potrzebujemy do tego wtyczki Quality Check.
Ustawienia -> Wtyczki (dolny lewy róg) -> Pobierz nowe wtyczki -> Znajdujemy Quality Check -> Instalujemy i restartujemy Calibre.

Gdy zrobiliśmy wszystko poprawnie po restarcie aplikacji powinna pojawić nam się dodatkowa ikona w pasku – Quality Check.
Wybieramy książkę/książki które chcemy poprawić i uruchamiamy opcje:

Po chwili pracy powinien pojawić nam się dymek, że wszystko zostało zmodyfikowane poprawnie. Książkę możemy już wysyłać do Kindle. Tag Personal magicznie rozpłynie nam się w powietrzu.
Jeżeli powyższa metoda nie zadziała oznacza to że plik źródłowy to hybrydowy plik MOBI7+KF8 i musimy go najpierw pociąć na części pierwsze przy pomocy pluginu KindleUnpack.
Addendum – Czysto techniczna strona problemu
Kilka słów dla osób zainteresowanych, jak to właściwie działa.
Każdy plik MOBI/AZW3 zawiera nagłówek z wieloma informacjami. Autorem, tytułem itp.
Dzisiaj interesują nas trzy specjalne pola:
- Pole nr 501 – CDE_TYPE – Określające typ książki.
- Pola nr 113 oraz 504 – ASIN – Zawierający unikalny numer identyfikacyjny książki.
Gdy kupimy książkę w Kindle Store, pola te będą odpowiednio wypełnione. W momencie gdy książka wyląduje na naszym czytniku okładka zostanie oddzielnie (!) pobrana z chmury Amazonu i umieszczona w pamięci podręcznej urządzenia.
Panuje ogólne przekonanie, że wpisanie w pole 501 wartości EBOK usuwa tag Personal. Jednak nie jest to prawda. Wymagany jest również numer ASIN.
Rozpatrzmy teraz kilka scenariuszy.
501 ustawione na EBOK. 113 i 504 niezdefiniowane/puste.
- Tag Personal.
- Okładka niskiej rozdzielczości. Ta, która jest zapisana we wnętrzu pliku MOBI/AZW3.
501 ustawione na EBOK. 113 i 504 zawierają prawdziwy numer ASIN.
- Brak tagu Personal.
- Okładka wysokiej rozdzielczości pobrana od Amazonu.
501 ustawione na EBOK. 113 i 504 zawierają fałszywy numer ASIN.
- Brak tagu Personal.
- Brak okładki. O dziwo Kindle w tym wypadku nie używa okładki niskiej rozdzielczości.
Tutaj do akcji wkracza magia Calibre. Przy tworzeniu pliku AZW3/MOBI Calibre ustawia pole 501 (EBOK) i generuje fałszywy numer ASIN.
Zaraz, zaraz, ale według powyższej rozpiski to nie powinno działać. I nie działałoby gdyby nie fakt, że w trakcie wgrywania książki na czytnik Calibre wmusza plik z okładką do pamięci podręcznej urządzenia. Należy pamiętać że Calibre wgrywa okładkę zdeklarowaną w rekordzie książki – nie okładkę zawartą w jej pliku.
Wszystkie okładki lądują w katalogu: /system/thumbnails/ – te dodane przez Calibre są kolorowe.

Katalog ten istnieje jedynie na modelach które mają opcje wyświetlania okładek w bibliotece. Schemat nazwy plików: thumbnail_{asin}_{cdetype}_portrait.jpg
Warto dodać, że nic nie stoi nam na przeszkodzie by te pliki podmieniać. Możemy sobie tak ustawić dowolną okładkę dla dowolnej książki :-)
I jeszcze parę słów od Roberta:
Dziękuję Pawłowi Jastrzębskiemu za zajęcie się tematem, okazuje się, że nie jest prawdą to, co pisałem w poprzednim artykule, że nie ma 100% pewności dotyczącej okładek. Paweł poświęcił rozgryzieniu tego problemu sporo czasu – niestety Amazon jest bardzo skąpy w dostarczaniu dokumentacji do formatu MOBI i większość wiedzy dotycząca m.in. okładek pochodzi z rozpracowywania tych plików przez użytkowników.
Natomiast to co przeczytaliśmy wyżej, potwierdza wniosek z dnia wczorajszego – jeśli chcemy mieć idealny plik, trzeba go na czytnik wysyłać po kablu.


{kind=link}
Świetnie wyjaśnione!!! Od teraz już nie będę bardziej leniwa niż leniwiec:) i wszystko ślicznie jeszcze raz wrzucę po kabelku :) widzę że warto!!!
Takich artykułów mi brakowało! :)
Chyba najwyższa pora zrobić w końcu porządek w książkach :)
Niby mam ich niewiele na razie, ale lepiej zacząć teraz, niż później się męczyć.
Artykuł świetny, konkretna porcja wiedzy i do tego przystępnie opisana.
Dobra robota Pawle!
Do idealnej konwersji brakuje jeszcze wtyczki Hyphenate, o której kiedyś pisałeś. Działa świetnie, polecam.
Nigdy o tym pluginie nie pisałem. Ale faktycznie wygląda ciekawie :-)
Robert pisał :)
A co do poradnika to świetny. Szkoda, że niecałe 2 tygodnie temu sprzątałem swoją kindlowo-caibrową bibliotekę i o tych detalach nie wiedziałem :/
A tak z innej beczki – czy widok „okładkowy” jest dla was aż tak istotny? Ja od początku mam „listę”, bo się więcej na ekranie mieści.
/me również. Sam w zasadzie nigdy nie przejmowałem się okładkami…
Na Kindlu nie trzymam więcej niż 20-30 książek, a to oznacza max 6-7 stron widoku okładkowego. W takim wypadku fajnie jak ładnie wygląda :). Nie potrzebuje zatem by więcej się mieściło.
Raz na miesiąc robię przegląd, co kolejne przeczytam, co przeczytałem. Akurat taka czynność z okazji ładowania (nie podłączam w międzyczasie mojego PW, co by bateria jak najdłużej mi służyła).
Dla mnie jest bardzo istotny. Jestem życiowym pedantem i potrzebuję mieć w mojej bibliotece odpowiednio ustawione tagi, książki posortowane w cykle etc. Widok okładkowy jest oczywiście mało ważny przy samym wgrywaniu pliku na czytnik, ale nie wyobrażam sobie czytać książki bez okładki ustawionej jako wygaszacz ekranu, źle sformatowanej lub coś w tym stylu.
To zasadniczo ta sama książka, ale książki można odbierać na różne sposoby. To ta sama różnica, co między oglądaniem filmu na dużym telewizorze, w wysokiej rozdzielczości i na wygodnej kanapie a oglądaniem tego samego filmu w kiepskiej jakości na małym komputerowym monitorze stojącym na biurku. Po prostu kwestia tego, jak istotna jest dla kogoś otoczka mediów w odbiorze tychże mediów.
Robert pisał.
http://swiatczytnikow.pl/jak-podzielic-wyrazy-w-e-bookach-kf8-lub-epub/
Mam problem z konwersją już od dłuższego czasu.
Posiadam pierwszą wersję Paperwhite i niestety przy konwersji książek w opcjach „Wyjściowy Mobi” muszę zaznaczyć „old” jako typ pliku. W innym wypadku przy przesyłaniu mailem dostaje komunikat od Amazonu o problemach z konwersją, podobnie plik przesłany po kablu w ogóle się nie otwiera. Macie jakieś pomysły?
Przestań robić MOBI. Zobacz czy problem występuje jak robisz plik AZW3.
AZW3 działa, dzięki. Czy to znaczy, że z konwersją za pomocą Calibre jest coś nie halo skoro Amazon nie rozpoznaje formatu pliku?
Różnie bywa. Dużo zależy od plików zródłówych. Ogólnie rzecz biorąc konwersje do MOBI łatwiej zepsuć :-)
Wielce przydatny artykuł. A informacja o ASIN tłumaczy, dlaczego zrezygnowałem z wysyłania książek w chmurę amazonu (pomijam pozbawiania książek formatu kf8, który niekiedy jest „niezbędny”, np. H. Potter, czy Hobbit :) ).
Gdy próbowałem wysyłać książki wszystkie traciły okładki i przeglądając chmurę miałem „puste” okładki. Ja tego nie mogłem znieść i wysyłam wszystko po kabelku. Teraz wiem dlaczego tak się dzieje.
Jedyny minus jak dla mnie przy wysyłaniu przez kabelek, to brak synchronizacji zakładek, podkreśleń, ostatniej strony :(.
Szkoda, że Amazon raczej tego nie zmieni, dla niego nie ma w tym żadnego interesu, żadnego zysku z poprawienia tego.
„Uwaga! Włączenie tej opcji uniemożliwia synchronizacje informacji o ostatnio przeczytanej stronie gdy używamy wielu urządzeń.”
A to w ogóle jest jakaś synchronizacja przy przesyłaniu przez kabel?
Nigdy tego nie testowałem.
Pytam z czystej ciekawości, co właściwie daje profil wejściowy i wyjściowy? I czy czy zauważyliście, że dla profilu „Kindle” w opisie jest rozdzielczość 525 x 640? A dla „Generic e-ink” 590 x 775, czyli bardziej odpowiadający standardowej rozdzielczości Kindla?
Czemu rozdzielczość jest taka a nie inna nie jestem w stanie ci powiedzieć. Pytanie trzeba było by skierować do K. Goyala – autora Calibre. Ale osobiście już się nauczyłem że jeżeli on coś mówi o czytnikach to ma racje :-)
Sam profil jest używany do wewnętrznej magii Calibre. Nie jestem w stanie ci wypunktowywać na co dokładnie to wpływa przy eksporcie do KF8 ale wiem że na profilach opiera się np. dobór rozmiaru czcionek, marginesów czy odpowiednie formatowanie rysunków.
Po tych 2 artykułach o zakamarkach działania czytników Kindle chyba muszę pożegnać się z przekonaniem, że to Onyksy są dla majsterkowiczów. ;-)
Oohoho. To jeszcze nic. Nie widziałeś jeszcze jaką magię odprawiają ludzie odpowiedzialni za jailbreaka :-)
Osobiście moim ulubieńcem jest człowiek który uruchomił Windowsa 95 na Kindle :-)
Masz moze jakiś link do tego tematu? :) Zainrygowal mnie…
http://www.mobileread.com/forums/showthread.php?p=2600537
Ha, czekałem na taki komentarz. :-)
Jeśli ktoś chce mieć idealnego e-booka, musi się trochę pomęczyć, chociaż akurat procedura z Calibre jest bardzo prosta. Ale i tak temat nie jest dla każdego – jeśli np. komuś nie przeszkadza „personal” na okładkach (lub w ogóle nie korzysta z widoku okładek), to nie musi się przejmować.
Inne czytniki mają swoje zagwozdki – mam i Onyxa i od niedawna Kobo Mini – i nie każdy e-book ma tam okładkę, nie mówiąc o słynnych problemach formatu EPUB z polskimi literami…
Jeśli ktoś chce mieć idealnego e-booka, musi się trochę pomęczyć
Ech, ciekawe co stało się z podejściem „płacę-wymagam”.
W większości książek muszę przerabiać przynajmniej odstępy między akapitami:
P {...; margin-top: 0cm; margin-bottom: 0cm}Świetny artykuł :-)
Dzięki za wyjaśnienia teoretyczne stojące za problemem. :-)
Dziękuję! Ten artykuł i komentarze pod rozważaniami na temat „Mailem czy po Kablu” rozwiązuje wszystkie problemy jakie miałem z konwersją zakupionych książek. Aby mieć perfekcyjnego ebooka potrzebujemy trzech wtyczek do Calibre: KindleUnpack, Hyphenate this, oraz Quality Check. :)
KindleUnpack to ciężka artyleria. Ale faktycznie przydatne gdy kroimy jakieś opornego pacjenta.
Dlaczego ciężka artyleria? Formatowanie pozostaje oryginalne. Znasz inny sposób na użycie Hyphenate this na pliku MOBI7+KF8?
PS: Sposób na „Personal” z wtyczką quality Check u mnie nie działa niestety. Przetestowane na dwóch plikach zakupionych dzisiaj w woblinku.
Ta wtyczka działa jedynie z niehybrydowymi MOBI. Najzwyczajniej w świecie zmienia ona tylko 1 znaleziony nagłówek. A czytnik używa drugiego – KF8.
W tym wypadku musisz też użyć KindleUnpacka i wyodrębnioną cześć KF8 potraktować Quality Checkiem.
Czyli jednak KindleUnpack jest niezbędny dla większości książek które obecnie możemy kupić w polskich księgarniach. 5 na 6 książek które ostatnio kupiłem były w formacie MOBI7+KF8. Może kiedyś twórcy hyphenate i qualitycheck zaktualizują swoje działa tak by obsługiwały również hybrydowe mobi.
Twórcy pluginów nie maja nic do powiedzenia. Calibre potrzebuje zmian. I z tego co ostatnio rozmawiałem z autorem – Nie jest zainteresowany wprowadzeniem obsługi przerabiania MOBI hybrydowych.
Przynajmniej na dzisiaj. Cała para idzie w nową wersje Sigila.
Żeby chociaż KindleUnpack potrafił wypakować kf8 i umieścić od razu „w książce”. Do tego najlepiej hurtowo :-).
ps. Paweł J. – rewelacyjny opis.
Bez problemu się da tego dokonać jeżeli posiadamy podstawowe pojęcie o Pythonie. Kod odpowiedzialny za splita to praktycznie biblioteka. Bez problemu można go zastosować do tego o czym mówisz.
Ludzie co Wy robicie. To nie my mamy naprawiać sobie książki żeby wyglądały należycie. One już po zakupieniu powinny wyglądać jak trzeba.
Dzisiaj załadowałem na czytnik „Widnokrąg” Myśliwskiego. Patrzę i przecieram oczy. Marginesy zajmują prawie 25% szerokości strony. Co się dzieje? Zaglądam do plików a tam body style width: 466px. Dobrze, że nie mam czytnika HD z szerokością 800px bo straciłbym ponad 40% szerokości na marginesy. Oczywiście marginesy powinny być, ale nie takie grube. Czy Myśliwski zasłużył na to, żeby tak zostać wydany?
Moim zdaniem skład e-książek to po prostu dziedzina w której wydawcy dopiero raczkują. Wiele osób myśli kategoriami książek papierowych – zrobię raz i wszędzie będzie to wyglądało tak samo.
Niestety jak widzimy praktycznie każdy model czytnika ma swoje dziwactwa i złożenie książki tak by prezentowała się godnie na jak największej ilości czytników to nie lada sztuka :-)
Tak jak Paweł pisał – tutaj wielu wydawców nie radzi sobie jeszcze z robieniem e-booków, przykładów nie trzeba daleko szukać. Ale jest też druga strona czyli niekompatybilność sprzętu czy całego systemu. Kindle ma swoje problemy, inne czytniki mają swoje.
Paweł, Robert,
Ok, wydawcy raczkują. Ile powinniśmy im jeszcze dać czasu?
Nie wiem czy dobrze Was zrozumiałem, ale chyba nie uważacie że te marginesy, o których pisałem wcześniej, to przypadłość mojego czytnika („każdy model czytnika ma swoje dziwactwa”, „niekompatybilność sprzętu czy całego systemu”). W ebooku w stylach dla znacznika body jest napisane, że szerokość tekstu to 466 pikseli i tak czytnik wyświetla. Proponuję taką szerokość dla znacznika body ustawić dla swiatczytnikow.pl, a w przypadku uwag stwierdzić, że strona dopiero raczkuje i że przeglądarki mają problemy z kompatybilnością.
Zle mnie zrozumiałeś.
Oczywiście że to źle sformatowany e-book. Nawiązywałem bardziej do sytuacji gdzie osoba która go robiła oglądała swój wynik pracy tylko w jednym programie/na jednym urządzeniu. I u niego prawdopodobnie wyglądało to zadowalająco.
Nie trzeba być geniuszem, żeby wiedzieć że ustawienie szerokości body w px jest złym pomysłem :)
W ogóle ustawianie szerokości dla body to zazwyczaj zła praktyka – jeszcze marginesy w jednostkach względnych przejdą, ale szerokość jako taka to już nie za bardzo.
To ja jeszcze z takim pytaniem (jako świeżak):
jeśli księgarnia daje mi przy pobraniu do wyboru Epub czy Mobi, to ma jakiekolwiek znaczenie, który format wybiorę? Przy założeniu, że i tak zaraz przekonwertuję do Azw3. (Podejrzewam, że nie ma różnicy. :P)
A poza tym oczywiście dziękuję i Pawłowi i Robertowi za poprzedni artykuł. Od dziś wreszcie wiem, jak to się je i wszystkie książki mają okładki bez etykiety. (Tylko coś dzielenie wyrazów nie chce zaskoczyć.) A niestety jestem pedantycznym pedantem, który musi mieć tu niemiecki Ordnung. ;)
W tej sytuacji lepiej pobierać EPUB bo może on być troszkę lepiej sformatowany od MOBI – większość wydawców najpierw przygotowuje właśnie EPUB, potem dopiero go konwertują do MOBI.
To wszystko zależy od tego czy Kindle powstał przez zwykłą konwersję z EPUB-a czy jednak ten EPUB był dostosowywany pod Kindle’a.
Przy powieściach nie ma to zazwyczaj znaczenia. Przy bardziej skomplikowanych książkach już tak.
Ok, dzięki wielkie! :)
Przeczytałam, pokiwałam głową i dalej nie rozumiem dlaczego mam piękne oryginalne lub własne okładki bez personal (konwersja do old mobi, wysyłanie tylko po kablu) nie robiąc niczego innego jak tylko zostawiając puste pole tam gdzie jest PDOC lub EBOK. Po prostu wykasowuję cokolwiek tam jest. Żadnych super ustawień powyżej opisanych, acha zawsze wyjściowy mam „Kindle Paperwhite”.
Hyphenate this brzmi interesująco.
Bo możliwe że w ustawieniach konwersji Calibre masz wszystko tak jak trzeba – albo książki ściągnięte z księgarni też już mają wszystko ustawione. :-))
Dokładnie. Ta konfiguracja którą podałem to nie jedyna z która tagi/okładki działają poprawnie.
Mam pytanie jak ustawić w Calibre wyjustowanie tekstu z pominięciem tytułów rozdziałów ?
Bo zdarza mi się ,że po użyciu pluginu Hyphenate This! treść tytułu (jak jest dłuższy) na czytniku jest rozciągnięta.
Używam czytnika Nook Simple Touch
Dawno się nie bawiłem w konwersję w calibre, ale sądzę, że wystarczy w sekcji gdzie masz dodatkowego CSS-a, wpisać:
p {text-align:justify;}
h1, h2, h3 {text-align:left !important;}
Pierwsza linijka może nawet nie być potrzebna jeśli już cały tekst jest wyjustowany.
Założenie jest takie, że nagłówki są zrobione tagami h1, h2, h3. Jeśli książka jest kupiona to niemal na pewno tak jest.
Bardzo ci dziękuję za pomoc :-)
Tak podejrzewałem ,że trzeba dodać jakąś regułę w css.
Ustawienie profilu wyjściowego,wyjustowanie,wtyczka dzieląca wyrazy i można czytać.
Dziękuję Robertowi i Pawłowi za artykuły.
Fajnie, że zadziałało. Wiedziałem, że calibre ma taką opcję, ale nigdy jej nie testowałem :)
Więc jakbyś chciał poprawić coś innego to wystarczy dopisać CSS-a.
Fajna sprawa – dzieki dla autora!
Można też sprzedać kindle, a zamiast tego kupić sobie normalny dobrej klasy czytnik i nie męczyć się z paskudnymi formatami plików Amazon’u.
Moc twoich argumentów przemawiających za „paskudnością” MOBI jest porażająca.
Ah. Zaraz. Nie podałeś ani jednego.
Każdy format ma swoje wady i zalety.
W przypadku EPUB-a dochodzą jeszcze kwestie oprogramowania/sprzętu na którym go odczytujesz.
Za to EPUB ma tą zaletę, że łatwiej go modyfikować bo nie jest formatem binarnym.
Ten poradnik akurat nie ma nic wspólnego z formatem, a raczej z faktem, że Amazon w celu ułatwienia swoim uzytkownikom podziału treści na czytniku, podzielił pliki na książki i inne dokumenty. Uznał jednak, że książki to są pliki z ich księgarni, natomiast inne to wszystkie inne pliki pochodzące z innych żródeł. Zapewne, dla uzytkownika, który jest klientem docelowym taki podział ma sens, tyle że dla nas, którzy w wiekszości zaopatrujemy się w książki poza systemem Amazonu, już nie.
Popieram :-)
Ja nawet nie patrzyłem w stronę Kindle podczas wybierania żadnego z moich czytników. Po prostu wiem (między innymi dzięki temu blogowi), że Kindle jest zbyt ograniczony i ograniczający :-)
Mój Kindle (pomimo stosowania się do wszystkich zaleceń przy konwersji do azw3) wciąż bezdyskusyjnie odmawia mi pokazywania numerów stron. Gdzieś wyczytałem, że aby ta funkcja zadziałała, trzeba wpierw zakupić jakiś ebook z Amazonu. Miał ktoś już taki problem?
Zobacz czy na czytniku po wgraniu plików prócz AZW3 pojawia się również plik APNX o tej samej nazwie.
Plik APNX się pojawi jeśli książka będzie wysyłana na czytnik z poziomu Calibre (przycisk „Prześlij na urządzenie”).
Tak, plik APNX znajduje się na swoim miejscu, jednak książka wciąż pozbawiona jest numeracji. Krótko mówiąc, załamuje mnie trochę ten Kindle, człowiek prawie na nic czasu nie ma, a jeszcze po nocach przesiaduje i myśli jak tu te pierońskie numerki do swoich ebooków dodać :/. Ehh, gdyby Onyxy były takie szybkie i zgrabne.
Na wszelki wypadek zapytam – co masz na myśli pisząc, że nie ma numeracji? Nie wiem jak jest w przypadku PW ale w starszych czytnikach aby zobaczyć numer strony trzeba wcisnąć MENU, nie jest on wyświetlany stale.
Tak, zdaję sobie z tego sprawę. Mam od niedawna nowego PW i cóż, chyba pozostaje mi zadowolić się wyliczaniem procentowym.
Przy okazji warto wspomnieć o sposobie na ręczne ustawienie liczby stron, tak aby była zgodna z rzeczywistą liczbą stron w książce papierowej (dane te znajdziecie np. na LubimyCzytac.pl po kliknięciu na link „więcej informacji”).
Sposób ten jest podobny do opisywanego kiedyś przez Roberta zastosowania wtyczki „Count Pages” (pobierającej liczbę stron z GoodReads) i polega na dodaniu własnej kolumny „Liczba stron” a następnie wpisaniu jej nazwy w konfiguracji urządzenia w polu „Kolumna użytkownika, z której należy pobierać liczbę stron”.
Kolumnę można dodać w ustawieniach Calibre -> sekcja „Interfejs” -> opcja „Dodaj własne kolumny” -> przycisk „+” (Dodaj kolumnę użytkownika). Nazwa wyszukiwania: pages , Nazwa kolumny: Liczba stron , Typ kolumny: liczby całkowite , Format liczb: {0:,} . W konfiguracji urządzenia (Urządzenie->Konfiguruj urządzenie) w ostatnim polu („Kolumna użytkownika z której należy pobrać liczbę stron”) należy wpisać #pages . Wystarczy teraz wpisać liczbę stron (bezpośrednio w kolumnie „Liczba stron” na liście książek lub w „Edycji metadanych” na zakładce „Własne metadane”) i Calibre nie będzie obliczać liczby stron tylko ustawi taką jaka została podana. W efekcie uzyskamy bardzo zbliżony do rzeczywistego układ numerów stron. Idealnie oczywiście nie będzie ale i tak dużo dokładniej (i szybciej) niż przy automatycznym wyliczeniu liczby stron przez Calibre.
A ja przy okazji tak ciekawego artykułu zapytam jeszcze o czcionki, bo nie do końca to rozumiem.
W Klindla można „wbudować” jakąś własną czcionkę (były artykuły Roberta na ten temat). Ale używana będzie ona tylko do tych książek, które nie mają ustawionej na sztywno innej czcionki, tak?
A jeśli przy konwersji Calibre wybiorę sobie jakąś inną (którą mam na PC) i polecę mu wbudować ją w książkę to w ebooku takowa się pojawi?
I jeszcze jedno – jeśli mam jakąś zakupioną książkę, która ma niestandardową czcionkę i chciałbym jej użyć w innym ebooku to jak można podejrzeć jej nazwę? Albo nawet „wyciągnąć” ją z pliku jeśli jest osadzona i jeśli to wogóle możliwe…
Michał
Nie wypowiem się o niestandardowych czcionkach – nigdy ich nie używałem. Na 100% jest to wykonywalne.
Plugin KindleUnpack powinien móc wyciągnąć czcionkę.
Czcionka osadzona w książce pojawi się na Kindlu. Często używam niestandardowych czcionek bez najmniejszych problemów. Musisz po jej otwarciu wybrać z czcionek opcję „publisher font”.
Wyciągnąć czcionkę z książki w formacie AZW3 lub EPUB też jest dość łatwo. Możesz użyć Calibre, nawet bez dodatkowych pluginów (opcja popraw książkę -> rozpakuj książkę; czcionki pojawią się w katalogu Fonts), albo Sigil (w przypadku EPUB) – wystarczy otworzyć książkę i wyjąć z katalogu „Fonts”.
Ah. Fakt. Zapomniałem że Calibre może rozpakowywać bez pluginów.
Po przekonwertowaniu i podzieleniu wyrazów calibre nie otwiera mi ksiązki. Poza tym dodaje ją ponownie do biblioteki…
Witam,
A jak skonwertuję epub do kf8 w Calibre, to będzie ok?
Tak.
Czy jest sens zmiany formatów MOBI na KF8 dla starego Kindle Classic? Jeśli on nie obsługuje okładek to czy zobaczę jakąkolwiek różnicę???
Ja ciągle używam Kindle Keyboard :-)
Tak. Rożnica jest.
A tak dla laika co powinienem zauważyć?
Jest tylko jeden sposób by się o tym przekonać – samemu porównać.
Racja sorry za spam. I dzięki za wyjaśnienia.
W artykule http://swiatczytnikow.pl/wszystko-co-trzeba-wiedziec-o-kf8-czyli-nastepcy-formatu-mobi/ podałem m.in. przykład książki z Woblinka na Kindle Keyboard.
Dzięki – przegapiłem ten artykuł.
Jestem nowym użytkownikiem Kindla, więc nie irytujcie się moimi pytaniami:-)
Zastosowałem ustawienia opisane w artykule. Zapomniałem jednak ustawić w Konwersji wyjściowego pliku jako AZW3 zatem przekonwertowało mobi/mobi co i tak dało efekt w postaci usunięcia notatki „personal” i wyjustowania tekstu etc. Nastepnie, na próbę przekonwertowałem mobi do AZW3 i okazało się jak napisałem powyżej, że Calibre nie może go otworzyć. Żąda wskazania programu powiązanego z tym rodzajem plików i ostrzega o dodaniu ponownym pliku do biblioteki. Czy nie mam jakiejś wtyczki do Calibre?
Nawiasem mówiąc rozwiązania opisane w tym artykule mają sens kiedy nie korzysta się z chmury, prawda? Po zassaniu książki z chmury i tak będzie miała oznaczenie „Personal”.
Ustawienia->Zachowanie i zaznacz „Użyj wewnętrznej przeglądarki dla:” AZW3.
@Paweł Jastrzębski
Stary format Amazonu nazywa się MOBI7, a nie MOBI6.
Warto to poprawić, bo może wprowadzać zamieszanie do i tak już wystarczająco skomplikowanego dla zwykłego człowieka tematu :)
Dowód: http://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf
Racja. Głupia literówka.
I wszystko byłoby pięknie, gdyby Calibre nie robił „siana” z kodu HTML książek :(
Ja po zobaczeniu kodu, który mi Calibre przygotował po przetworzeniu książki przestałem korzystać z tego narzędzia ;)
Jedynie Sigil daje mi pełną kontrolę nad modyfikacjami kodu. Mobi uzyskuję z pliku ePub wyprodukowanego przez Sigil narzędziem kindlegen, czyli tym „pobłogosławionym” przez Amazon ;)
Gdyby tylko KindleGen nie był tak paskudnie wolny i posiadał jakąkolwiek konfiguracje….
Warto zaznaczyć że on produkuje w pełni hybrydowe pliki MOBI (M7+KF8+SOURCE) więc o ile nie czyścisz go po konwersji to około połowa pliku to dane których nie potrzebujesz.
Kindlegen z domyślną opcją kompresji (c1) tworzy w większości wypadków plik wynikowy w ciągu 5-10 sek, a nawet krócej. Dodatkowo pokazuje ostrzeżenia, o tym, że np. okładka jest małej rozdzielczości itp.
Co do hybrydy – tu masz rację – niepotrzebne jest źródło. Do wycięcia źródła można zastosować KindleStrip. Choć to narzędzie też nie do końca dobrze się sprawdza: http://www.mobileread.com/forums/showthread.php?t=96903&page=3
Generalnie ponieważ korzystam z Kindle na Adroidzie, iOS, PC, Mac oraz z urządzeń Classic i Paperwhite wolę korzystać z oficjalnych narzędzi Amazona, tym bardziej, że format KF8 i Mobi nie są w pełni udokumentowane i wiele funkcji, które daje np. Calibre stało możliwe po zastosowaniu inżynierii wstecznej. Takie działania nie dają gwarancji, że coś w przyszłych wersjach oprogramowania Amazonu nie posypie się.
Tak. Czysto tekstowe pliki są parsowane szybko. Schody zaczynają się w bardziej skomplikowanych tworach/treściach z duża ilością grafiki.
„Nie są w pełni udokumentowane” to mało powiedziane :-) Dokumentacja nie istnieje. Amazon dostarcza tylko informacje jak zrobić poprawnie plik EPUB dla KindleGena. WSZYSTKO co wiemy o właściwym MOBI7/KF8 pochodzi z reverse engineeringu.
Uważam Kindle za bardzo dobrą rodzinę czytników ale poziom zamknięcia ekosystemu Amazon często mnie osłabia.
Trudno się nie zgodzić z uwagą na temat zamknięcia ekosystemu Amazonu. Ale fakt faktem, że dokumentacja KF8 jest lepsza od tej dotyczącej MOBI7 – na temat MOBI7 Amazon nie opublikował niemal nic i wszystko trzeba testować.
Jeśli puścisz kindlegena oraz calibre na tym samym EPUB-ie to raczej kindlegen nie będzie wolniejszy.
I warto zauważyć, że calibre (jeśli chodzi o kod odpowiedzialny za konwersję) i kindlegen zostały stworzone w dwóch różnych celach:
Calibre zostało stworzone, aby zwykli czytelnicy mogli sobie szybko i prosto przekonwertować książki pomiędzy formatami bez znajomości HTML-a i poszczególnych formatów.
kindlegen został stworzony z myślą o autorach, wydawcach oraz profesjonalistach, którzy tworzą książki z przeznaczeniem dla Kindle Store. W takim przypadku poczekaniu chwili dłużej nie stanowi wielkiego problemu. Tak samo to że plik zawiera źródło+MOBI7+KF8 też nie stanowi problemu, ponieważ Amazon te pliki od siebie oddziela i wysyła właściwy format do osoby, która ją kupiła.
Więc ciężko porównywać te dwa narzędzia, bo nie do końca zostały stworzone w tym samym celu. A calibre naprawdę robi straszne rzeczy z kodem i jeśli robisz plik od zera to kindlegen jest pewniejszy jeśli chodzi o efekt niż calibre.
Ba. Ja wręcz jestem zmuszony do używania KindleGena bo żadne inne narzędzie nie jest w stanie poprawnie stworzyć KF8 komiksowego.
Patrze na to z trochę innej perspektywy bo w moim wypadku KindleGen jest najwolniejszym elementem procesu jaki przeprowadzam.
Ale to jest spowodowane tym o czym mówisz – To narzędzie zostało stworzone od innych celów. I w porównaniu z Amazonowym Kindle Comic Creatorem spełnia swoje zadanie :-)
Ah i zapomniałem wspomnieć o największej pułapce KindleGena.
Calibre nie obsługuje podwójnych kompletów nagłówków w plikach MOBI.
Wszelkie skrypty obecnie edytują jedynie pierwszy komplet nagłówków znalezionych w pliku. A to zawsze MOBI7.
Często nowicjusze dwoją się i troją próbując edytować nagłówki i dziwią się że nie widać efektu na maszynach używających KF8 :-)
Dla kronikarskiej skrupulatności: Należy wtedy wyciągnąć cześć KF8 z hybrydowego MOBI. Np. pluginem KindleUnpack.
Po internecie krąży też zmodyfikowana cześć KindleUnpacka która potrafi wyedytować pola 113, 501 i 504 w obu nagłówkach na raz bez cięcia pliku.
Wow, nie wiedziałem że wydawca musi zrobić EPUBA-a żeby z niego zrobić MOBI. Wydawało mi się, że musi zrobić robotę 2 razy albo nawet 3 po wprowadzeniu KF8. To dla mnie informacja trochę szokująca ;) Dzięki.
To oczywiście zależy od metody pracy, ale „najprostszy” sposób jest taki:
1) Robisz jednego HTML-a dla wszystkich formatów i wspólnego CSS-a (i składasz to do EPUB-a)
2) Dopisujesz CSS-a tylko dla EPUB-a
3) Dopisujesz CSS-a tylko dla KF8
4) Dopisujesz CSS-a tylko dla MOBI7
Niestety często kończy się to na kroku pierwszym, bo wielu osobom nie chce się pisać oddzielnego CSS-a dla każdego z formatów, zwłaszcza, że np. format MOBI7 wymaga czasami użycia HTML-a, który musi być usunięty w EPUB2 (bo EPUB2, w przeciwieństwie do formatu Kindle, nie wspiera oficjalnie „media queries”, których w formacie Amazonu można użyć do ukrycia treści w jednym z formatów) – a to wymaga trochę dodatkowej pracy.
Artykuł super. Wyrzuciłem połowę książek z mojego KT i zrobiłem konwersję. Zdecydowana poprawa jeśli chodzi o wygląd ebooków. Pojawił się tylko problem – nie chce mi zmieniać rozdziałów jak zrobię slide z góry na dół i odwrotnie. Po takim geście ląduje na wstępie książki. Co ważne pozostawione ebooki sciągnięte z Cloud działają normalnie. Wie ktoś w czym problem ??
Prawdopodobnie calibre zepsuł plik NCX. Jeśli tam są wyodrębnione poszczególne rozdziały to nawigacja pomiędzy rozdziałami działa. Jeśli nie to niestety nie.
Jak masz oryginalnego EPUB-a albo go odzyskasz z pliku dla Kindle za pomocą KindleUnpack (wtyczka do calibre lub samodzielny skrypt w pythonie) to możesz zmodfikować plik toc.ncx. Jak nie wiesz jak to możesz użyć np. Sigila i w nim użyć opcji generowania spisu treści (tej która generuje NCX a nie HTML-a).
Trochę więcej szczegółów na temat toc.ncx i Kindle pod koniec tego tekstu: http://blog.epubeo.pl/struktura-pliku-epub/
Dzięki za szybko odpowiedź. Sprawa była w sumie prozaiczna – trzeba było trochę poczekać aż Kindelek wszystko sobie wczyta, przemieli i mogę sobie teraz przerzucać rozdziały bez problemu :)
O tym nie pomyślałem :)
Po objawach wyglądało na to, że zepsuła się nawigacja, a więc NCX był pierwszym podejrzanym.
Świetny artykuł, ale raczej nie będę wszystkiego od początku przerabiać ;) Oby więcej takich artykułów o możliwościach Calibre. Wiele osób na pewno z tego skorzysta.
Dzięki za super artykuł.
Mam jeden, jedyny problem – konwersja z mobi do azw3 usuwa mi strukturę rozdziałów. Po prostu po kliknięciu „Go to” nie mam żadnych rozdziałów, jedynie początek, koniec, lokacja itd.
Jest jakiś sposób żeby te rozdziały przy konwersji w Calibre zachować?
Popatrz na komentarz soulafeina.
No niestety, to nie rozwiązuje mojego problemu. Rozdziałów jak nie było, tak nie ma, a ja nie dysponuję plikiem epub, a mobi (z niego idzie konwersja do AZW3) :(
Większości komentarzy i tak nie rozumiem, ale ja głupi kupiłem sobie kindla, żeby książki czytać ;)
W każdym razie pozdrawiam wszystkich Macgyverów
Świetny artykuł. Wielkie dzięki.
Jeszcze zastanawiam się jak zlikwidować zbyt duże marginesy z lewej strony. Czy da się to gdzieś ustawić w Calibre?
W calibre przy konwersji masz opcję gdzie możesz wpisać dodatkowy CSS. Wpisz tam:
body {margin-left:0 !important;}
Jak nie zadziała to wpisz jeszcze:
p {margin-left:0 !important;}
Świetny art. Dzięki.
Mam pytanie z pogranicza i może off topic ale temat mnie nurtuje i nie mogę znaleźć odpowiedzi. Zdarzylo mi się parę razy po kupnie książki w formacie mobi, wrzuceniu jej do Calibre, konwersji i wysłaniu e-mailem do chmury Amazonu otrzymanie na czytniku tylko jednej strony z informacją 'Książka zabezpieczona znakiem wodnym’. Jeśli zrobie wszystkie kroki jak powyżej ale bez konwersji to mam całą książkę? Pytanie dlaczego?
Mam pytanie o okładki. Jest w tym katalogu sporo plików zajmujących 0 bajtów. Zgaduję, że to okładki, których brak. Rozumiem, że można by wgrać samemu w to miejsce poprawne okładki. Jak rozpoznać, który plik odpowiada za którą książkę?
Okładek się nie wgrywa oddzielnie. Muszą one być dodane do pliku. Więc jak chcesz dodać okładkę do pliku dla Kindle to możesz dodać ją w calibre, a potem zrobić konwersję (ale to Ci może zepsuć formatowanie) albo jak masz źródło EPUB-a to możesz dodać do niej odwołanie w content.opf (szczegóły – http://blog.epubeo.pl/sekcja-guide-epub-kindle/) i przepuścić ją przez calibre (nie jestem pewien czy zadziała) lub przez kindlegena.
Ale chyba dodanie okładki nie jest warte zachodu :)
Hmm cała zabawa polega na tym że na nowych Kindle pliki które mają fałszywy ASIN w sobie nie używają okładek z pliku i trzeba je wgrywać odzielnie.
Calibre się tym zajmuje. Więc tak jak pisze Rafał – jak długo okładka będzie w metadanych Calibre to okładka zostanie wgrana w trakcie uploadu samej książki.
Robienie tego ręcznie z poziomu katalogu jedynie dodaje ci pracy.
O, to tego nie wiedziałem :)
Skąd się bierze ten fałszywy ASIN? I rozumiem, że problem występuje tylko na Kindle Paperwhite? Chciałbym to przetestować, bo mnie zaskoczyłeś.
Polecam przeczytać ostatnia cześć tego artykułu…
Problem występuje na każdym modelu który w widoku biblioteki ma opcje wyświetlania okładek.
No tak, nie przeczytałem jeszcze całości. Dzięki :)
Ja od siebie dodam, że tego problemu nie ma w aplikacjach Kindle dla Androida, iOS, czyli na tabletach, smartfonach okładki są ;)
Ten fałszywy ASIN to jest numer UUID 4 (tzw. random UUID): http://en.wikipedia.org/wiki/Universally_unique_identifier#Version_4_.28random.29
Tu masz przykładowy generator takich UUID4: http://www.uuidgenerator.net/version4
Już wiem jak dodać okładki jeśli z chmury plik ściągnął się bez niej.
Każda książka jest zapisana jako plik Nazwa_Numer.azw
Teraz wystarczy w katalogu \system\thumbnails\ (jest ukryty) skopiować plik jpg z okładką pod nazwą
thumbnail_Numer_EBOK_portrait.jpg
i mamy i książkę na chmurze (z wszelkimi tego plusami) i okładkę.
Dobrze kombinujesz, ale nie do końca to co napisałeś ci zadziała. Nie możesz nadać nazwy z 'EBOK’, bo książki ściągnięte z „Personal Documents” mają PDOC. Możesz przeanalizować sposób działania mojego skryptu automatyzującego cały proces: http://blog.blaut.biz/2014/01/skrypt-lekarstwo-na-brakujace-okladki-w-kindle-paperwhite-w-jezyku-python.html
Racja. Błąd przy kopiowaniu. :)
thumbnail_Numer_PDOC_portrait.jpg
Pytanie za 100 punktów. W pliku EPUB mam osadzone fonty, żeby na 100 % były osadzone w pliku AZW3 to muszę włączyć jakąś opcje w Calibre ??
Po prostu sprawdź czy zadziała. Jeśli masz poprawnie osadzone czcionki w EPUB-ie to użycie kindlegena (http://www.amazon.com/gp/feature.html?docId=1000765211) jest pewnym rozwiązaniem, żeby je zachować.
Jestem pod wielkim wrażeniem.Dzieki tej stronie kupiłam kilkanaście dni temu mój pierwszy czytnik-PW,dzięki tej stronie wiem jak się poruszać (a jestem hmmm…umiarkowany talent komputerowy) .Tłumaczycie wszystko jasno i przejrzyście,dzięki
„I nie działałoby gdyby nie fakt, że w trakcie wgrywania książki na czytnik Calibre wmusza plik z okładką do pamięci podręcznej urządzenia.”
A skąd ta okładka? Z wnętrza pliku, z amazonu, czy z jakiejś bazy calibre?
Z twojej biblioteki Calibre.
Czy coś przegapiłem – w ustawieniach Calibre – czy w każdym wypadku po konwersji do azw3 (wraz z dzieleniem wyrazów) „gubi” rozdziały ? (w sensie przy przeglądaniu książki – gestem „od dołu” – już ich nie pokazuje i nie możena miedzy nimi przeskakiwać; nie pokazuje też ile do końca rozdziału ?
Da się to jakoś „naprawić” czy coś namieszałem ?
Ja apeluję do wszystkich początkujących „grzebaczy”. Uważajcie w pracy z Calibre. Ten program naprawdę mocno ingeruje w oryginalny kod książki i możecie później mieć do czynienia z różnymi niespodziankami. Jeśli już koniecznie chcecie dłubać to zachowajcie sobie – w postaci backupu – oryginalne pliki.
ok – rozumiem, że „namieszałem” ;-)
Ale czy możesz napisac „jak i co” ustawić w Calibre żeby mi nie likwidowało rozdizałów ? Nie chciałbym rezygnować z możliwości dzielenie wyrazów – dużo lepiej mi się tak czyta …
PS nie mogę tego odnaleźć – a wydaje mi się, że gdzieś (w komentarzach ?) ktoś pisał jak zlikwidować (w sposób zautomatyzowany) puste linijki pomiędzy wersami (które o ile pamiętam ponoć pojawiają się przy konwersji z pdf’ów)
Ktoś kojarzy taką „opcję” ?
Zakładam, że przed konwersją na 100% rozdziały były, czy tak?
Potrzebuję dodatkowych informacji.
1. Zainstaluj program Kindle Previewer: http://www.amazon.com/kindleformat/kindlepreviewer
2. Otwórz tę „niedziałającą” książkę w tym programie.
3. Wybierz z menu „View” opcję „Book Information” i napisz tu jakie informacje zobaczyłeś.
Interesują mnie przede wszystkim pozycje, gdzie widnieje „Not specified”.
Hmm… z lektury tego wątku: http://www.mobileread.com/forums/showthread.php?t=202786 wynika, że raczej nic się tu nie zdziała.
Ot, po prostu jeśli załadowałeś plik do Calibre w staszym formacie Mobi Calibre po prostu ignoruje obecność tzw. logicznego spisu treści (NCX) i przy konwersji po prostu go pomija, co właśnie skutkuje brakiem nawigacji po rozdziałach.
W książkach w formacie Mobi oraz nowszym (KF8) występują dwa rodzaje spisów treści: zwykły HTML-owy oraz logiczny (NCX) i oba są bardzo ważne i potrzebne. Kindle Previewer pokazuje, czy w danym pliku są te spisy treści.
Wykorzystam artykuł o CALIBRE aby zapytać o najnowszą wersję 1.12
Czy po aktualizacji również wam zniknął język polski? Nie mam go ani w głównych ustawieniach programu ani w metadanych książki w możliwościach wyboru – powiem szczerze, że spore zaskoczenie!!!
Ktoś wie czy można to samemu naprawić czy trzeba czekać na jakąś kolejną łatę lub co gorsza wywalać i instalować starszą wersję :/
Przy próbie użycia wtyczki Quality Check, w celu naprawienia numeru ASIN i pozbyciu się tagu „Personal”, wyskakuje mi błąd. „MOBI book to update: Bastion / Stephen King
No ASIN found, using uuid: 0c767896-886f-4944-a330-4f8c952c35e4”. W efekcie czego napis Personal dalej znajduje się na okładce. Wiecie jak temu zaradzić?
Książka nabyta w Virtualo.pl
To nie błąd. Zmiana została wykonana poprawnie.
Prawdopodobnie to hybrydowy MOBI. W tym wypadku żadne proste narzędzie ci tego niestety nie naprawi.
Czyli musiałbym jakoś wyciągnąć z tej hybrydy plik, który mnie interesuje? Plik waży 4,5MB, co by faktycznie wskazywało na hybrydę, ale z drugiej strony książka ma 1700 stron.
I jeszcze jedno pytanie, jako, że w środowisku e-czytelników jestem świeży. Czy eBooki zakupione w różnych księgarniach, mogą różnić się między sobą? Bo np. jedna książka zakupiona w Virtualo ma na frontyspisie informcję, iż to Virtualo przygotowywało eBooka. Z kolei w innej pozycji (także z Virtualo), jako twócę eBooka jest podana firma eLib.pl.
A jednak proste narzędzi mi to naprawiło. Faktycznie było to hybryda. Wtyczka KidnleUnpack wyizolowała plik sfromatowany Kf-8, jego waga zmniejszyła się do 2.5 z 4.5Mb. Następnie należy usunać książkę z biblioteki Calibre oraz z urządzenia. Dodać ponownie czyste KF-8 i potraktować Quality Check. Tag Personal znika.
Dzięki na naprowadzenie na dobre tory.
Widzę że ci się udało. Większość osób jakie znam sobie by nie poradziło – dlatego nie nazwałem tego „prostym” sposobem.
Podobnie postąpiłem z książką zakupioną w Ebookach Allegro (działa ślicznie) ale mam problem z opublikowaniem highlight’u na Facebooku. Dostaję komunikat: „Unable to post. Please try again.”
Czy to znany problem? Ktoś wie jak go obejść?…
Malbuk.. Strzał w dziesiątkę! O to właśnie chodziło. Wielkie dzięki za ten komentarz. :) Dzięki niemu właśnie z sukcesem przerobiłem pierwszą hybrydową książkę. Formatowanie zostało tak jak chciał wydawca a napisu Personal już nie ma. Pozdrawiam i dziękuję.
Dzięki Malbuk! Wreszcie pozycje z Publio nie mają tej irytującej etykietki i wchodzą na Paperwhite jako książki, nie dokumenty :)
Czy wie ktoś może jak przy pomocy Calibre zlikwidować niepotrzebne interlinie? Cały pięcioksiąg „Wiedźmina” Sapkowskiego jest tak sformatowany przez CDP, że nawet pomiędzy kolejnymi dialogami są duże przerwy w tekście, jakby dodatkowe akapity, zupełnie bez sensu. Strasznie jest to irytujące jak się czyta, tym bardziej że to nie była najtańsza pozycja; w tej cenie mogli się lepiej postarać.
pytałem o to kiedyś bo wydawało mi się, że ktoś kiedyś w jakimś komentarzu podawał sposób a nie mogę znaleźć … i na razie odpwoedzi brak …. może tutaj ktoś coś podpowie ;-)
Znalazłem.
Ustawienia->opcje wspólne->wygląd->usuń odstępy pomiędzy akapitami.
Przekonwertowałem całego Sapkowskiego i działa bezbłędnie.
pozdrawiam
Można też w polu dodatkowy CSS dopisać:
p {margin-top:0 !important; margin-bottom:0 !important; text-indent:1em !important;}
Przy powieściach powinno to mieć oczekiwany efekt. Przy książkach bardziej złożonych może to zepsuć sporą część formatowania. Ale możesz sprawdzić, żeby zobaczyć czy wygląda to tak jak chcesz.
Hej,
Zainstalowałem wtyczkę do pobierania okładek na książki (Lubimyczytać) ale nie działa… Pomimo iż książka jest w serwisie, tytuł jest poprawny, po wciśnięciu klawisza Pobierz okładkę Calibre nie znajduje w ogóle jej w bazie… Dlaczego? Ktoś miał podobny problem i jak go rozwiązać? (dodam, że z innych serwisów też okładek calibre nie znajduje)
tez mam podobny problem, z checia bym poznal rozwiazanie, bo oprocz z lubimyczytac, to takze z googla mi nie znajduje zadnych okladek.
W tym wątku jest opisane aktualne rozwiązanie Waszych problemów.
Użyłem kindle unpack na moim hybrydowym mobi, podzielił mi na trzy pliki azw, mobi i cover, użyłem Quality Check w Calibre na azw, zapisałem na dysku i przełożyłem na kindle.
Fakt, pasek personal mi zniknął, ale razem z okładką :/
Co robię źle ?
Chciałbym dowiedziec sie czy dobrze mysle i uzyskac pomoc co dalej w kwesti takiego zagadnienia:
mam dosc sporo ksiazek w formacie .txt i chciałbym z nich zrobic .mobi
czyli robie z .txt- html a z tego pozniej przez program calibre .mobi tylko jak z txt zrobic własciwy html ?? tak zeby tekst co ma byc na jednej stronie był na jednej stronie a nie teskt co ma byc na jednej to tekst z 3 jest na 1 to mnie nurtuje bo z reszta dam sobie jakos rade poki co bo nast etapem bedzie tworzenie spisu tresci i robienie numerow stron ale fajnie by było stworzyc taki poradnik dla takich jak ja zołtodziobow co chce jednak od poczatku do konca nauczyc robic mobi bo jak widze to nic trudnego tylko trudno mi znalezsc wiedze w tym zakresie potrzebna od zaczecia bo tutaj owszem widze ale to wszystko jest juz dla osob ktore cos wiedza i sie orientuja w temacie i im łatwiej to wszystko jest ogarnac wiec prosze was spolecznosc o pomoc w tym konkretnym problemie :) z gory dzieki
Calibre pozwala na konwersję bezpośrednio z .txt do dowolnego innego formatu wyjściowego, bez potrzeby przechodzenia przez HTML-a.
A jeśli chcesz mieć większą kontrolę nad tym jak .mobi będzie wyglądał to przeczytaj http://swiatczytnikow.pl/szybka-konwersja-z-uzyciem-libre-office-i-calibre/ i http://www.czytajbezdrm.pl/2012/formatowanie-tekstu/
Dziekuje bardzo w wolnej chwili pewnie w weekend zapoznam sie z matriałami i bede prubował jesli nadal bede miał problemy to bede pytał o wskazowki :)
choc mam jeszcze jedna bo ma kindle peapierwhite i tam ejst gdzies przegladarka internetowa podobno i mozna korzystac z niej jesli ma sie wi-fi oraz jak przesłac komus ksiazki na kindle jesli jestesmy w dwoch roznych miastach ale ktos ma tylko kindle i wi-fi w domu ?
Witajcie,
Mam mały problem, uczę się angielskiego poprzez czytanie napisów z filmów, ale jak w kindle paperwhite 2 używam formatu TXT to słownik angielski działa, lecz Vocabulary Builder nie dodaje sprawdzanych słow. Jak konwertowałem napisy z TXT na MOBI lub AZW3 to znowu nie działał mi słownik angielsko-polski który wgralem na kindla z strony http://www.bumato.pl/.
Pozdrawiam
A ustawiłeś w Calibre język ebooka na angielski?
Tak, zaraz po uruchomieniu.
A ja powiem tak: po przeczytaniu komentarzy odnośnie problemów z formatowaniem i koniecznością zabawy niczym czarodziej-informatyk, przeszła mi chyba ochota na Kindle ;-)
Słowo „konieczność” jest grubą przesadą. Żadnej „konieczności zabawy” nie ma. Zwykłemu użytkownikowi Klindle do wygodnego czytania wystarczą ebooki przygotowane przez wydawnictwa/księgarnie.
Owszem zdarzają się w nich błędy ale czy w książkach papierowych ich nie ma?
Format elektroniczny ma tą przewagę nad papierem, że perfekcjoniści (do których kierowany jest ten artykuł) mogą sobie samodzielnie poprawić niedoróbki i to robią.
A widząc, jak niewiele potrzeba wysiłku aby stworzyć „plik idealny”, narzekają, że wydawcy nie robią tego sami. W tych narzekaniach jest dużo racji ale mogłeś przez nie odnieść wrażenie, że oryginalne ebooki do niczego się nie nadają. Na szczęście tak nie jest.
Dużo racji jest w tym co piszesz. Sam zakupiłem kilkanaście ebooków jednak w laptopie nie czyta się wygodnie. Dlatego zacząłem się zastanawiać na Kindle. Jest jednak jeszcze jeden problem. Kupuję również e-wydania gazet i gdy dziś napisałem do sklepu, w którym zwykle kupuję, czy mają wersję gazet na Kindle to mi odpisano, że takowych nie ma. Do czytania tego typu wydawnictw potrzebny jest zwykle jakiś program komputerowy (czy to PC, Android albo WPhone). Tak więc w moim przypadku Kindle nie mógłby być „od wszystkiego”. O ile wiec na „smartfonie” można więcej plików obsłużyć, o tyle na Kindle czyta się z pewnością lepiej. No i powstaje rozdwojenie jaźni w postaci nurtującego pytania: „co wybrać?”. Pewnie, że można się „obkupić” we wszystko co na rynku dostępne tyle, że z radością użytkowania nie ma to wtedy zbyt wiele wspólnego. Muszę więc sprawę z Kindle poważnie przemyśleć. Pozdrawiam :-)
Ja borykam się z innym problemem. Oto po konwersji niektórych książek z pliku źródłowego .htm do .epub, .pdf, .azw3, czy .mobi, calibre układa rozdziały w przypadkowej kolejności. Słowem książka zaczyna się np od ostatniego rozdziału, lub gdzieś w środku. Zauważyłem również, że strony w tych przypadkach nie są numerowane w wydruku. Czytnik calibre pokazuje wprawdzie numer strony w legendzie, ale nie odpowiada on rzeczywistemu numerowi strony w książce. Czy jest na to jakaś rada, czy wina leży po stronie plików źródłowych? Czy istnieje jakaś możliwość ułożenia rozdziałów książki w odpowiednim porządku, czy na czytniku (mam Kindle 4) zaczynać czytać od końca?
Witam
Mam problem przy konwersji z *.pdf-a. Wygląda to tak, że litera „ż” się nie konwertuje i zamiast tego pojawia się litera S z „daszkiem”. Reszta liter wyświetla się prawidłowo.
Wie ktoś co z tym można zrobić?
P’s Oczywiście przy przejściu na Mobi i AZW3
Czuję się na to zbyt tępa. :( Niektórych opcji nie zauważyłam w programie, może była już aktualizacja?
Działa wyśmienicie! :)
Zabawna sytuacja.
Wcześniej, nie używając Calibre, a wgrywając książki poprzez zwykłe przeciągnięcie plików do „documents”, czasem nie działały mi okładki. W takim wypadku zgłaszałem księgarni i poprawiali. Zapewne usuwając numer ASIN.
Teraz na odwrót, wgrywając przez Calibre, potrzebujemy numer ASIN (fałszywy), aby mieć okładkę i pozbyć się tagu personal.
Każdemu księgarnie nie dogodzą :D
Walczę i walczę z „Personal” – Spróbowałem na „Wicher Wojny” – znikło :) … ale uparłem się na Muminki. Mam już 3 z serii kupione w dwóch różnych księgarniach. Niestety ciągle Personal, a tytuł jest akurat na dole okładki i mnie to wkurza.
Czy coś jeszcze trzeba czasem zrobić oprócz FIX ASIN for Kindle Fire?
Wrzucam mobi – nie konwertuję na AZW3.
Moje narzędzie ExtractCoverThumbs 0.2 odpowiednio przetwarza okładki, tak, żeby pasek Personal nie zasłaniał okładki książki: http://blog.blaut.biz/2014/05/aplikacja-extractcoverthumbs-0-2-opublikowana.html
Działa z plikami w nowym formacie KF8 (AZW3) najlepiej z tymi pobranymi z chmury Amazonu :)
Po wielu próbach Fix itd w końcu przekonwertowałem oryginalne mobi do AZW3 i napis PERSONAL zniknął.
A można by prosić o przeróbkę z opcją aby napis personal po prostu zniknął?
Jeśli chcesz synchronizować książki poprzez chmurę Amazonu to się nie da. Innych opcji nie rozważam. A już na pewno nie kaleczenia książek przez calibre.
Calibre nie kaleczy książki jeśli nie używasz konwersji.
Ja używam Calibre bez użycia konwersji.
Wystarczą dwie wtyczki Quality Check i Kindle Unpack. Okładki są widoczne, a personal znika.
A plik Mobi jak uzyskujesz? kindlegenem? Podejrzewam, że nie. Jeśli calibre robi plik Mobi, to najpierw generuje tymczasowo plik epub, który cierpi na classitis, czyli w moim rozumieniu jest już okaleczony, bo jest tak dalece zmodyfikowany, że można śmiało mówić, że powstał inny plik o tej samej treści. Ten nowy plik, w przypadkach ekstremalnych może wyglądać i zachowywać się inaczej niż oryginał.
Kupuję plik mobi w księgarni, zapisuję na dysku i przeciągam do Calibre.
Mówisz, że podczas tego procesu Calibre tworzy plik epub ?
@quiris: Classitis i bardzo płaska struktura html w przypadku czytników z niezbyt bystrym prockiem jest zaletą, a nie wadą. Szybkość czytania i przetwarzania przez czytnik jest o wiele szybsza niż stado zagnieżdżonych div i p i h i do tego jeszcze warunkowo ostylowanych. Zresztą coś takiego robią też amazonowe toolsy do konwersji, wiec o co chodzi?
Ogólnie trochę przesadzasz z tym okaleczeniem (ale oczywiście masz do tego pełne prawo). Jasne, calibre idealne nie jest, ale bez przesady.
@Eltanin:
…przeciągam do Calibre.
Mówisz, że podczas tego procesu Calibre tworzy plik epub ?
nie, do tego momentu mobi jest jak był (chyba że będziesz miał drm i wtyczkę do zdjęcia tegoż), dopiero konwersja robi jakieś zmiany (sieczkę, jak twierdzi quiris :P ),
jest jeszcze kruczek przy zapisie do katalogu/czytnika, i jeśli masz zaznaczoną opcje aktualizacji metadanych w locie to zapisany już będzie trochę zmieniony plik (ale bez
sieczkarnizamiany na epuba).Classitis to jakieś dziwactwo, które zostało zaordynowane przez różnego rodzaju automaty i które nie ma nic wspólnego z semantyka kodu i utrudnia jego analizę. Nic nie jest w stanie go obronić. Można przygotować plik stosując prawidłową semantykę kodu HTML i prawidłowe semantyczne selektory w pliku CSS i takie są w większości przypadków ebooki aktualnie przygotowywane. Te najgorsze, najciemniej przygotowane, ciężkie do analizy to właśnie głównie produkty calibre.
Pisząc, że kindlegen robi to samo, nie piszesz prawdy: http://blog.blaut.biz/2014/06/sieczkarnia-calibre-w-akcji-porownanie-do-kindlegena.html
Każdy ma prawo korzystać z takich narzędzi, z jakich chce, ale powinien mieć pełną wiedzę, co się dzieje z jego ebookami i nie podoba mi się to, że próbuje się wmawiać, że calibre pozwala uzyskać idealny plik i że calibre nie kaleczy kodu. Bo to po prostu nieprawda. To, że tego kalectwa często nie widać, po zrenderowaniu, nie znaczy, że go tam pod spodem nie ma.
Sprawa trochę podobna do generowania plików html w edytorach tekstu typu Ms czy Libre Office… Tyle że programu kindlegen nie można używać komercyjne.
BTW, próbowałeś tego?
Asymon, z kindlegena możesz korzystać komercyjnie, o ile masz odpowiednią umowę z Amazonem: Any commercial use of this Software outside of the authorized purposes requires a separate agreement with Amazon.
I wydaje mi się, że polskie firmy przygotowujące pliki Mobi do dystrybucji przez księgarnie stosowne umowy posiadają, bo bardzo rzadko zdarza się, że Mobi ściągnięty z księgarni nie jest wynikiem działania kindlegena.
Mobipocket Creatora nie próbowałem, bo korzystam z Mac OS na co dzień…
że próbuje się wmawiać, że calibre pozwala uzyskać idealny plik i że calibre nie kaleczy kodu. A kto tak twierdzi? Owszem, pozwala uzyskać dość przyzwoity ebook czytelny na większości czytników.
Umyka Ci że czytników epub i sposobów renderowania jest kilkaset (no dobra sposobów renderowania jest mniej).
To, że tego kalectwa często nie widać, po zrenderowaniu, nie znaczy, że go tam pod spodem nie ma.
Jak 99.9% nie widzi różnicy to po co się przejmować? Osobiście wolę czytać książkę, a nie jej źródła :P i obawiam się, że nie jestem wcale w tym odosobniony.
Skoro samo dodanie mobi do Calibre nic nie zmienia, to jak dla mnie Calibre jest idealnym narzędziem. Konwersje jest zbędna. Jeżeli plik mi nie odpowiada, zgłaszam to do księgarni.
Używam wprawdzie wtyczki do łamania DRM, ale jeżeli dobrze rozumiem to niezabezpieczonych ebooków ona nie tyka. Jeżeli zaś chodzi o zabezpieczone dodaję je tylko dla celów archiwizacji.
Nic nie zrozumiałeś, ze tego co tu napisane. Skoro piszesz: Wystarczą dwie wtyczki Quality Check i Kindle Unpack. Okładki są widoczne, a personal znika. to znaczy, że dokonujesz konwersji. Kropka.
.
quiris, w którym momencie dokonuję konwersji?
Quality Check tylko dadaje numer ASIN, nie wpływa na tekst.
Kindle Unpack natomiast jedynie dzieli plik na jego składowe: MOBI i AZW.
Nie widzę tu konwersji.
Jak w wypadku Quality Check masz racje to Kindle Unpack nie dzieli pliku tylko rozmontowuje go na części pierwsze i montuje go ponownie. W wielu wypadkach rożni się on oryginalnego pliku który został użyty by stworzyć MOBI.
Niekoniecznie wyglądem ale zmiany strukturalne są gigantyczne.
A tak przy okazji – do czego służy Kindle Unpack? – Jak poszukałem w sieci to ściąga się jako „Kobo Utilites.zip” Mam Paperwhite 2. I teraz używam tak naprawdę po kolei dla kupionych mobi:
1. Konwersja do AZW3
2. Count Pages – ilość stron
3. Edytuj metadane – ściągam opis, ewentualnie podmieniam okładkę
4. Sprawdzam spis treści – ewentualnie poprawiam – Edytuj spis treści
5. Quality Check – Fix – Fix ASIN for Kindle Fire
6. Wysyłka po kablu
czy coś mam zmodyfikować w moim działaniu?
Teraz mam okładki „belki” Personal
kiedyś spróbowałem „Dopracuj Książki” ale tylko mi rozwaliło spis treści.
KindleUnpack służy do rozpakowania pliku Mobi na składowe części – mobi (azw) + kf8 (azw3), plik źródłowe (html, css, obrazki, etc.)
A tu masz wątek (stronę domową) aplikacji KindleUnpack: http://www.mobileread.com/forums/showthread.php?t=171529
Całe nieszczęście świata Kindle’owego polega na tym, że format MOBI/KF8 jest formatem całkowicie zamkniętym nieustandaryzowanym, którego szczegóły zna tylko Amazon. Wszelkie narzędzia manipulujące plikami MOBI/KF8 niepochodzące od Amazonu (np. calibre, KindleUnpack) zostały zbudowane w oparciu o inżynierię wsteczną i jako takie muszą mieć błędy, które powodują, że nie jest możliwe zbudowanie stuprocentowo zgodnego z formatem MOBI/KF8 pliku wynikowego. Stąd właśnie wcale nierzadkie przypadki odrzucania plików MOBI/KF8 przez chmurę Amazonu. W tej chwili jedynie oficjalne programy Amazonu: kindlegen oraz Kindle Previewer (korzystający wewnętrznie z kindlegena) dają gwarancją poprawnego przygotowania pliku MOBI/KF8.
Czyli nie ma ŻADNEGO sposobu na edycję metadanych plików hybrydowych MOBI/KF8 bez użycia konwersji ?
Jest jeden nieoficjalny skrypt Pythonowy który potrafi edytowac oba nagłówki na raz ale nie działa on z MOBI nie tworzonymi KindleGenem i to czysty kod – żadnego GUI itp.
Dzięki za ten poradnik, bardzo fajnie wszystko wyjaśnione!
Przestała działać po aktualizacji wtyczka: Quality Check
Mam Win7 64
Tak więc znowu jestem skazany na belkę PERSONAL :(
Czy można w jakiś sposób ręcznie edytować pola, gdzie wpisywany jest numer ASIN bez użycia Calibre, które dopisuje od siebie jakiś niepotrzebne rzeczy do pliku MOBI.
Ten przepis już nie działa. Mam nadal Personal.
Witam, a ja mam problem bo wciąż nie widzę okładek na moim paperwhite2, proszę o pomoc
Osobom, które pragną widzieć okładki proponuję zapoznanie się z alternatywnym narzędziem: http://blog.blaut.biz/2014/05/aplikacja-extractcoverthumbs-0-2-opublikowana.html
Witam
Tak ślęczę nad konwersją i nie umiem sobie poradzić z przypisami w Calibrze. Czy plikiem źródłowym jest odt czy zapisany jako html Calibre odsyła do spisu utworzonego na ostatniej stronie, poniżej ostatniego wersa. Wszystko niby działa, bo * gwiazdka przy słowie które chce objaśnić pięknie odsyła na koniec książki. Sam powrót też nie jest uciążliwy – jedno klikniecie i jesteśmy z powrotem w tekście. Jednak wolałbym, aby przypis był na dole strony, a nie na końcu książki. Czy da się coś takiego ustawić? Czy trzeba się pogodzić z przypisami na końcu książki?
Pozdrawiam i dziękuję za ewentualne odpowiedzi.
Pomóżcie. Po dwóch godzinach walki padłem. Mam ściągnięty plik mobi. W przeglądarce książek calibre widać tekst książki. Po wysłaniu do kindla (zarówno przez email jak i po kabelku z calibre) widać tylko okładkę i spis treści. Program calibre jak i kindla ustawiłem wg. powyższej instrukcji.
1. Spróbuj w Calibre to MOBI przekonwertować do MOBI – może plik się naprawi i będzie działał.
2. Ściągnij program Kindle Previewer i zobacz czy go otwiera.
Cześć. Kindle Previewer go otwiera. Konwertowałem to w programie Calibre. Jak zaczynam konwertować to format wyjściowy prawy górny róg okna ma być „mobi” , a po kliknięciu w ikonę niebieskiej strzałki „wyjściowy Mobi ” zostawić opcję format wyjściowy Mobi czy zaznaczyć AZW3? I jeszcze jedno czy w opcjach kindle zaznaczyć old czy new. Przepraszam za takie pytania, ale kondla mam od 2 dni i to moja pierwsza książka którą ściągnąłem.
wyjściowy MOBI, w opcjach zaznacz „old” albo „both”.
Zrobiłem jak mówisz i dalej kicha. W Kindlu jest okładka, jest spis treści i nic więcej :-(
Cześć, od razu przepraszam, że odgrzebuję stary wątek, ale mam dokładnie ten sam problem – po zmianie ustawień w Calibre, kindle nie czyta mi w ogóle plików MOBI. Poradziłeś sobie jakoś z tym problemem?
Od kilku dni mam Kindle Paperwhite. Pomimo zastosowaniu sposobu podanego powyżej i wielu prób w moim czytniku nie widzę okładek, gdy przesyłam pliki skonwertowane do AWZ3 w Calibre (zarówno kablem, jak i mailem). Jedynie pliki wysłane z konta w sklepach mają okładki plus, oczywiście tag Personal, ale to są MOBI, których edycja mi nie odpowiada. Czy istnieje jakiś działający sposób na okładki w Paperwithe?
Upload AWZ3 kablem na 100% działa poprawnie. Trudno mi powiedzieć co robisz źle.
Cóż, będę próbował dalej.
O co chodzi z tym tagiem personal? W czym jest problem?
Jak powinienem prawidłowo przygotować i wykonać konwersję poezji, która jest w postaci zwrotek. Wiersze mi się łączą do kupy i w żaden sposób nie mogę sobie poradzić, by na czytniku zachowany został układ wiersza. Coś pewnie (jakiś znak?) powinienem wstawić na końcu linijki wiersza, czy może (lub też) zmodyfikować jakoś ustawienia w calibre.
witam. Czy ktoś mógłby mi doradzić. Od kilku dni nie mogę wysłać z calibre pocztą plików. Pokombinowałem już setnie i wyszło na to, że konwertowane przeze mnie w calibre do mobi odrzuca. Potraficie podać przyczynę i możliwe rozwiązania?
pozdrawiam
ja
Świetny portal, fajny artykuł. Dzięki jego lekturze nabyłem na Święta Kindla PW2 jako prezent pod choinkę ….dla siebie (gdyż nikt nie zna naszych potrzeb tak dobrze jak my ;) ).
Czytam po kolei co ciekawsze artykuły, skonfigurowałem Calibre, przerzucam pierwsze książki (nie mam ich na razie za wiele, muszę poszukać jakiś świątecznych promocji na pozycje które od dawna za mną „chodzą”) i zauważyłem na jednej pozycji „Cmentarz w Pradze” Umberto Eco taki problem przy konwersji z EPUB do AW3 :
http://zapodaj.net/2f7af0b56e8cc.jpg.html – mam w ten sposób „zniszczone” formatowanie:
Jak widać przewężenie tekstu do kolumny jest trochę denerwujące – tym bardziej, że jak podglądam oryginalny EPUB sprzed konwersji , to nie posiada takiego błędu.
Konwersja przy użyciu calibre, wg. ustawień z artykułu.
Ma ktoś pomysł co może być przyczyną ???
Ja bym skonwertował wynik jeszcze raz do azw3 a jak nie pomoże to edytuj książkę i usuną odpowiednie znaczniki html
Spróbuję edycji – choć jeszcze nie wiem które znaczniki i w jakim programie wyedytować , ale pewnie jakoś się dowiem – jak w xml-u edytowałem skórki do Football Managera mając o tym mgliste pojęcie , to i tu powinno jakoś pójść :)
Przy okazji – mam powiedzmy 10 książek przygotowanych do przerzucenia na Kindla, każda ma okładkę i jak kopiuję je masowo na czytnik to z 1-2 pozycje gubią okładki. Za każdym razem są to inne pozycje – o co tu może chodzić ??
Mam tak samo, zupełnie nie wiem czemu tak się dzieje. Próbowałeś wrzucać po jednej? Może zadziała.
Hej,
W większości przypadków zadziałało, pojawił się tylko jeden kłopot – w jednej z książek , po wrzuceniu było wszystko ok, a po jakimś czasie samoczynnie okładka zniknęła. staram się to ignorować, choć nie ukrywam, że chciałbym poznać przyczyny ;)
Świetny tekst. Spowodował u mnie potrzebę posiadania poukładanej i posprzątanej bazy książek na Paperwhite2 :)
I tu pojawia się mój problem. Otóż w przypadku książek stanowiących serie w tytule na sam koniec wpisywałem numer serii. Niestety ta metoda zadziałała dla 20-30% książek (i nie wiem dlaczego). Poczytałem i postanowiem zastosować poniższą składnię przy kopiowaniu po kablu
{author_sort}/{series}/{title} {series_index}
I znów brak sukcesu – efekt identyczny jak wcześniej.
Jakiś pomysł co może nie działać? Akurat w tym wypadku wszystkie książki są kupione w formatach epub i mobi…
Mam problem z konwersją ebooka z .pdf do .awz3 albo .mobi, otóż .pdf na komputerze jest czytelny, natomiast po konwersji w calibre, na czytniku wszystkie wyrazy są podzielone spacjami na sylaby. Próbowałam konwertować ten plik na milion sposobów ale nic to nie daje, (ale np. spis treści nie jest podzielony).
Może już ktoś się spotkał z podobnym problemem.
Bardzo proszę o pomoc.
Witam. Mam ten sam problem. Rozwiązała już go Pani ?
Porobiłem porządki ze swoimi e-bookami, wszystkie okładki na swoim miejscu.
Mam PW 2i mam takie pytanie.
Czy po utworzeniu kolekcji, można zmienić jej obrazek, wyświetlany obok nazwy?
Jeżeli tak to jak?
Dzięki za odpowiedź
Witam serdecznie, po sformatowaniu książki do AZW3 czytnik nie wykrywa mi poszczególnych rozdziałów książki, to znaczy są widoczne na początku ale nie mogę się ani do nich przenieść (wywala mnie na początek książki), a w konsekwencji nie działa mi prawidłowo zczytywanie czasu do końca rozdziału, gdyż kindle paperwhite wykrywa wszystkie rozdziały na stonie 3. Czy można to jakoś skonfigurować i czy przypadkiem Przetwarzanie Heurystyczne nie odpowiada za to wszystko ?
Próbowałem stosować zalecenia i ustawienia z tego artykułu i zawsze plik wyjściowy jest zepsuty. Niektóre wyrazy są dzielone na zasadzie litera+spacja+reszta, dodawanych jest mnóstwo pustych wierszy. U mnie to źle działa…
Plik wejściowy to jak rozumiem EPUB lub MOBI? Dziwne, puste wiersze nigdy nie powinny być dodawane jeśli nie włączymy tego w ustawieniach konwersji.
A ja obstawiam, że wejściowo był to marnie złożony (choć przy konwersji w calibre to nawet mógł być idealny) PDF.
Czy ktoś wie jak scalić kilka-kilkadziesiąt książek w jedną?
Korzystałem ze strony FantastykaPolska.pl i zebrało mi się około 300 osobnych darmowych plików (najczęściej opowiadań) w bibliotece Calibre – fajnie by było zamiast tylu plików wysłać na kindle 1,2 ksiażki z tytułem np. FantastykaPolska.pl Tom I do 2014, Tom II I kwartał 2015 itp. – jeszcze jaby jakoś z automatu powstał spis treści…
Przestałem mozolnie ściągać około IV 2014 ze względu na tą ilość małych plików. ale w sumie gdyby to scalać w większe pliki…
Jaki to format? jeśli to EPUB to wystarczy rozpakować, wrzucić wszystkie pliki (x)html do jednego archiwum i wygenerować nowe pliki ze spisem treści (można w calibre lub sigilu) i przede wszystkim zbudować poprawny plik .opf (tu też pomoże sigil, ale jest to na tyle nieskomplikowane, że można też ręcznie).
mobi
Jeśli teksty masz w pliku .doc, to możesz wysłać go na swoje konto Amazon e-mailem lub Send-to-Kindle. Tam zostanie przekonwertowany do odpowiedniego pliku czytanego przez Kindle. Nie wysyłałem tak pliku ze spisem treści lub odnośnikami, więc nie wiem, czy spis treści by działał.
Dziękuję za odpowiedź. Mam Kindle od ilku lat, więc takie niuanse są mi znane. Jednak Send-to-Kindle oraz e-maile z tematem 'Convert’ nie zawsze dają dobry efekt. Natomiast mój problem dotyczy poprawiania plików już znajdujących się w pamięci czytnika, a zatem w formacie dla niego odpowiednim.
Witam,
Proszę o pomoc. mam Kindla PW2. Problem polega na tym, że konwertując niektóre książki… nie wiem dokładnie jak to opisać a nie umiem wrzucić screena, Otóż jak mamy zdanie Ala ma kota, słowo Ala jest w jednym, a ma kota w drugim akapicie. Tak jakby dzieli mi jedn zdanie na dwa wiersze. Nie jest to dla mnie jakąś straszną tragedią, ale miło byłoby się tego pozbyć. Z góry dziękuję za pomoc.
Czy jest możliwość zmiany globalnej wielkości miniatur, które zostają przesłane do folderu system/thumbnails w Kindle za pomocą Calibre?
Standardowa miniatura ma wymiary: 227 x 330. Pierwsza wartość (szerokość może się nieznacznie różnić) Jednak wszystkie okładki wysłane przez Calibre do Kindla mają mniejszą wysokość niż inne np. dodane przez Amazona czy przesłane emailem i zakupione w sklepie. Ręcznie da się poprawić miniaturki, ale wg. mnie mają większy rozmiar, ale jakość jest słaba.
Jeżeli jest taka możliwość to proszę o info gdzie to można zmienić. Dodam, że posiadam Calibre w wersji: 2.3.0.
Dzięki :)
Widzę możliwość konwersji do AZW4 w Calibre. Może ktoś coś na ten temat bo nigdzie nic a ciekawość spać nie daje.
Dla jednej ksiazki okladka mi znika. Widac ja chyba przez ulamek sekundy po wgraniu a pozniej znika. Dziwne. Reszta ksiazek mi dziala z okladkami…
Dodatkowo zauwazylem, ze w przypadku co najmniej kilku innych ksiazek mam inne okladki w kindle niz wgrywalem. Tzn. Wydaje mi sie, ze ten plugin co robi fix ASIN powoduje, ze dla czesci ksiazek sciagaja sie one z amazon i nadpisuja moje okladki? Czy moze jest jakis inny powod.
Ma ktos pomysl jak to naprawic?
Użyj programu ExtractCoverThumbs.
Choć jeśli nastąpiła już masakra ASIN (użyto numery, które są przypisane do innych książek) nawet to narzędzie może nie pomóc.
Pewnie wtedy usunąłbym wszędzie numery ASIN i program powinien zadziałać.
Bez ASIN ExtractCoverThumb nie działa. Opcja FIX ASIN w calibre dodaje fałszywy numer.
Ogólnie Kindle mający dostęp do sieci potrafi mocno nabałaganić. Znikające okładki to zabezpieczenie przed samowolnym dodawanie okładek do książek spoza Amazon Store. To dziadostwo pojawiło się jakiś miesiąc temu i jak dotąd nie ma na to lekarstwa.
Tzn. Wgralem swoja okladke np. do wiedzmina, ale widze inna okladke wiedzmina w kindle niz wgralem. Dla jednej ksiazki nie widze zadnej okladki. Chociaz po wlaczeniu czytnika przez ulamek sekundy cos tam widzialem ;). Z tego co rozumiem, prawdopodobnie kindle sam sobie podmienia okladki. Jeszcze sprobuje recznie podmienic plik jpg na pamieci kindla i tu 2 pytania:
1) Jak rozpoznac ktora okladka do ktorej ksiazki na pamieci kindle, robilem kilka prob z wgrywaniem jednej z ksiazek i mam 3 okladki w pamieci (wiec chce wykasowac)
2) Czy musi miec jakis konkretny format. Zakladam, ze jest pewien przedzial rozdzielczosci ktory moge uzywac?
Osiagnalem sukces, wydaje sie, ze poprzednia okladka mimo ze zrobiona przez calibre miala odrobine zle rozmiary (chyba ze czyms innym naprawilem, bo kombinowalem na wszystkie mozliwe sposoby). Po podmienieniu na inna (z tej samej ksiazki ale innego wydawnictwa) obrazek przetrwal w kindlu:).
Aha, kombinowalem też z reczna zmiana nazw okladek z inna numeracja w nazwie, a mianowicie 10 cyfrowym numerem, bo zauwazylem ze sam kindle wlasnie takie nazwy plikow tworzy (a nie numery z myslnikami posrodku). Tak czy inaczej da sie wygrac, choc do tej pory nie wiem ktora metoda zadzialala ;).
Ps. A ja myslalem, ze w Onyx i62 trzeba bylo z czyms kombinowac ;). Teraz bawie sie w zmiany formatow, naprawianie, numerow, podmienianie okladek, robienie ujemnych marginesow (za kazdym razem wymaga to recznego sprawdzenia jakies classy uzywaja zeby dla niej podmienic definicje marginesow, wiec nie ma tu chyba, prostego uniwersalnego kodu :) ).
Ps2. Z kindlem dokonalem czegos czego nigdy nie zrobilem z onyxem, a manowicie okazalo sie, ze spalem na nim, przynajmniej obudzilem sie naciskajac ramieniem na kindla z otwarta okladka. Juz myslalem, ze rekordowo szybko zniszczylem, w koncu nie tanie uzadzenie, ale na szczescie wszystko z nim w porzadku. Mysle, ze to szklo na przodzie uratowalo ekran ;).
Hej mam podobny problem nie wiem w jaki sposób ustawić okładkę, próbuje dodawać obraz w odpowiednich rozmiarach, ale nawet wtedy okładka nie jest widoczna, a nawet przy wejściu do książki, nie pokazuje mi okładki. Wygląda tak jakby po wgraniu na czytnik książki okładka była usuwana. Czy jest to związane z tym, ze mam jeszcze nie zarejestrowany kindle? Będę wdzięczna za pomoc.
Pomoc potrzebna, po zmianie laptopa i ponownej instalacji calibre zauważyłem pewną niedogodność. Kiedy teraz uruchamian funkcję „pobierz wiadomości” (różne rssy z blogów itp.) to pojawiają się one z tytułem składającym się z nazwy źródła ale bez daty pobrania, tak jak to wcześniej było. Przykład: „Świat Czytników” teraz versus dawniej „Świat Czytników 30 sierpnia 2016”. Gdzie to można ustawić, by do tytułu była też dołączana data pobrania?
Mam pytanie. Sukam rozwiazania (o ile takie istnieje), jak dokonać backupu ustawień Calibre. Mam w planach reinstakację systemu, chciałbym po niej mieć moje stare, kochane Calibre z takimi samymi ustawieniami, wtyczkami itp Czy możliwe jest dokonanie całościowego backupu, lub jakaś metoda pośrednia (np skopiowanie konkretnych plików czy katalogów)?
Oczywiście, że jest taka możliwość. To co skopiować zależy od systemu operacyjnego. Sam używam linuksa i OS X, więc tylko dla tych systemów mogę sprawdzić właściwe ścieżki.
To powinno pomóc: http://cyfranek.booklikes.com/post/1315999/calibre-jak-to-jest-zrobione-kopia-zapasowa-katalogu-e-bookow-i-ustawien-programu
Dzięki! W ten sposób zachowuję wszystko? Chodzi mi np o ustawienia wtyczki Hypernatate wraz z zainstalowanym słownikiem pl?
Przepraszam, ale nie sprawdzę tego teraz. Postaram się w piątek późnym wieczorem jeśli będzie aktualne.
Wg manuala tak, a jeśli jest inaczej to pomoże już tylko ręczny backup. Możesz śmiało założyć, że wszystkie ustawienia będą zachowane – ewentualnie słownik i inne pliki pomocnicze wgrasz od nowa – nie ma tego dużo.
Poradnik Cyfranka prowadzi jak po sznurku. Calibre działa jak wcześniej, wszstko zostało zachowane. Wielkie dzieki.
zrobilem wszystko jak w opisie ale po konwersji epub otryzmuje plik mobi, nie powienienm otrzymac formatu AZW3? Jak chce uzyc wtyczki dzielenie wyrazow to wyswietla mi sie tylko format epub do podzielenia nie pojawia sie mobi?
Wybierz MOBI i jako jego typ „both”.
Opisywałem to w nowszym artykule: http://swiatczytnikow.pl/jak-przy-pomocy-calibre-poprawic-e-booki-wysylane-na-kindle/
dzieki
Cześć wszystkim, posiadam Kindle 4 i sporadycznie z niego korzystam, najczęściej jakieś swoje teksty na nim czytam. Teraz trafiło mi się do przeczytania opowiadanie s-f zawarte w pewnej publikacji. Korzystając z tego manuala chciałem spowodować dzielenie wyrazów. Zrobiłem jak mniemam wszystko według instrukcji ale na czytniku nie dzieli mi wyrazów.
Co zrobiłem: skonwertowałem MOBI na AZW3, następnie użyłem „Dziel wyrazy”, to samo zrobiłem też dla wersji EPUB z identycznym rezultatem.
Co ciekawe w Calibre jak czytam to wyrazy są dzielone. Dla testów jakiś plik Wordowski sobie skonwertowałem i elegancko wyrazy się dzielą. Mam prośbę o pomoc co jest nie tak z plikiem lub co źle robię.
Dla ewentualnego odtworzenia moich działań opowiadanie nosi tytuł „To byliśmy my” i jest zawarte w periodyku Silmaris, link http://silmaris.pl/silmaris-2-2016/
Łączę pozdrowienia, Robert
https://www.NoFile.io/f/dsIK1PJN3li
Smacznego.
PS. Publikacja darmowa ze strony http://silmaris.pl/czasopismo/ – udostępnienienie niekomercyjne.
Zastanawiam się nad jedną rzeczą… Czy jest szansa, by wysłać książki na czytnik mailem (synchronizacja, dostępność w chmurze) a później (lub wcześniej) dograć do nich okładki w jakiś sposób po kablu?
Tylko mając zmodowany czytnik. Trochę o tym pisałem u siebie na blogu: http://eczytniki.blogspot.com/2017/01/extra-kindle-tools.html.
W skrócie: zapomnij. Chyba że jesteś hackerem/moderem…
Technicznie przeszkoda wygląda tak, że Amazon oznacza wszystkie pliki wysłane do chmury etykietą PDOC, a przy pobieraniu na czytnik informacja o tym trafia do bazy z której odczytywane są m.in. nazwy plików z okładką. Dla PDOC-ów oczywiście to pole jest puste. Mod naprawiający dba o to by te pola były wypełniane wg takiej samej konwencji jaka obowiązuje dla książek z Kindle Store.
Drogi, autorze świata czytników,
zaczytuję się w Pana serwis od dłuższego czasu i postanowiłem całą bibliotekę e-booków przenieść do calibre.
Wiem, że jest Pan doświadczonym użytkownikiem Calibre, proszę o podpowiedź: w jaki sposób opisywać książki mających kilku autorów, tak aby sortowanie było zgodne ze sztuką?
Gdy wymienię ich w polu po przecinku, sortowanie jest po imieniu.
Aż takim doświadczonym użytkownikiem nie jestem, ale według https://www.mobileread.com/forums/showthread.php?t=35824 jeśli książka ma wielu autorów, należy oddzielić ich znakiem „&”.
Np. „Grzegorz Górny & Rafał Tichy” – wtedy porządek sortowania będzie „Górny, Grzegorz & Tichy, Rafał” i da się wyszukiwać też po drugim autorze.
Dodatkowo można użyć wtyczki Quality Check i wybrać „Fix” i „Swap FN – LN” co zamienia w polu autor układ „Adam Mickiewicz” na „Mickiewicz, Adam”. Zmienia to całą bazę i nazwy katalogów. Z opisu:
Swap author names for the selected book(s) between FN LN and LN, FN order or vice versa
Niestety trzebia przerabiać wszystkie k kupione ebooki.
Dzięki, działa! :)
Dzięki za świetny artykuł! Mam jednak mały, już mnie irytujący problem. Wcześniej udało mi się wszystko ładnie zrobić (łącznie z użyciem Hyphanate, dar od bogów) z inną książką, ale teraz mam problem. Otóż czytałem ci ja książkę na czytniku, nową, świeżutką, ale właśnie była niewyjustowana i nie potraktowana Hyphanate, dlatego postanowiłem ją przerobić. Usunąłem ją z czytnika. Wrzuciłem do Calibre epuba, potraktowałem Hyphanate, przekonwertowałem na AZW3 i mobi. Przesyłam na Kundla i… klops. Na czytniku nie jest wyjustowana i nie ma podziału wyrazów, a jak otwieram w Calibre książkę, to wszystko jest ok. Co przeoczyłem? Męczę się już pół dnia z tym. Paperwhite 3.
Już wiem! Przeanalizowałem wszystko jeszcze raz. W opcjach wyjściowych, MOBI output, miałem ustawiony typ pliku MOBI – old. Po przestawieniu na both wszystko jest w porządku. Uff.
Najlepsze są problemy, które rozwiązują się same. :-)
Programiści w takich celach korzystają z metody gumowej kaczuszki: https://pl.wikipedia.org/wiki/Metoda_gumowej_kaczuszki
Bardzo przydatne :)
Hmm… Od około tygodnia jestem posiadaczem PW2 (z drugiej ręki) i próbuję przez Calibre stworzyć pliki, które odpowiadałyby moim oczekiwaniom.
Zależy mi tylko na:
– justowaniu tekstu,
– dzieleniu wyrazów
– nieco większych akapitach,
– podziałach strony przed początkami rozdziałów/nagłówków.
Jednak wciąż coś mi nie wychodzi – przeważnie docelowy plik albo nie ma okładki i ma podział wyrazów, albo ma okładkę i nie widać żadnych zmian. Jest mi ktoś w stanie napisać krok po kroku jak to najprościej zrobić? :D
Dodam, że póki co próbowałem tylko wysyłki przez maila, albo zapisania EPUB jako PNG i wysyłki na Kindla, żeby sobie sam to przekonwertował. I tak działa, ale nie ma okładki. Halp? ;)
Jako format wyjściowy podaj MOBI Both. Ewentualnie ten plik z podziałem wyrazów wgraj po kablu.
Cześć,
czy ktoś poratowałby podobnym poradnikiem dla Pocetbooka Touch Lux 3? Ogólnie dopiero zaczynam przygodę z Calibre, a zasób wiedzy zerowy. Może ktoś podeśle jakiś wskazówki opisujące temat od A do Z? Może też być Sigil.
Ale na Pocketbookach nie musisz nic kombinować :-) Jeśli masz poprawnie przygotowany plik epub, to nie ma zmiłuj, będzie wyświetlać się ładnie. Oczywiście możesz go sam „doszlifować”, chyba lepiej w Sigilu niż w Calibre, możesz zacząć np. tu:
http://swiatczytnikow.pl/tematy/sigil//
Poza tym, jak już otworzysz plik w Sigilu, sprawdzasz:
– spis treści,
– semantykę (okładka, początek tekstu itp.),
– metadane (autor, tytuł, język, opis),
– style (z tym potencjalnie najwięcej roboty, ale zwykle wystarczy zmniejszyć marginesy i wyjustować, jeśli chcesz dzielić wyrazy).
Ja pliki i tak trzymam w Calibre, więc potem jeszcze włączam wtyczkę dzielącą wyrazy, taki ebook dla mnie wygląda najlepiej, niestety Calibre psuje style. Jeśli nie dzielisz wyrazów, możesz zostawić wyrównanie do lewej, wyjustowany tekst ma brzydkie „dziury”, szczególnie przy większym rozmiarze tekstu.
Otwórz sobie dobrze zrobionego ebooka, na przykład coś Czarnego, skład robi im d2d, i przyjrzyj się jak to wygląda „od środka”.
I tyle.
W piątek przerzucałem na czytnik różne eBooki, mając nadzieje, że poprostu je odpalę i przystąpię do czytania. A tam jeden ebook z tekstem wysrodkowanym, inny bez żadnej reguły a to pogrubiony, a to zwykły, inny łamany w połowie zdania po pierwszych trzech zdaniach, inne z rozrosnietymi interlinniami lub z zerowymi. gdzieś jeszcze poczytam o konwersji w Sigilu?
Jeśli odpalasz pliki z „gryzoni” to tak jest…
Pogrubianie, wyśrodkowanie załatwisz stylami, otwórz ebook w Sigilu i przyjrzyj się plikom. Ale jeśli to faktycznie ebooki z chomikuja, to twórcy najczęściej nie przejmują się poprawnością stylów i jest bałagan. Zwykle jest robiony OCR skanów książki, czasem sprawdzony, czasem nie, potem konwersja z worda do pdf i do epub, też bez korekty – ważna jest ilość, nie jakość. Zresztą nawet dobrze przygotowany pdf źle się konwertuje do epub.
Nad poprawkami zwykle spędzisz tyle czasu, że jest to nieopłacalne, choć czasem się dość łatwo da poprawić taki plik. Można nauczysz się czytać takie coś, widzę czasem ludzi w autobusach, ja wolałbym się golić tępą żyletką i pić zimną kawę.
Co do Sigila – jak będziesz używał, to się nauczysz. „Oficjalny” podręcznik jest tu, ale tu naprawdę wystarczy praktyka i znajomość html+css.
Zauważyłem, że trochę treści nt. Sigila jest też na swiatczytnikow. Jak tylko znajdę chwile czasu to siadam i biorę się za obrabianie plików.
A czy jest możliwe stworzenie dla Kindla takiego pliku mobi, w którym będzie można włączać i wyłączać zarówno justowanie jak i dzielenie wyrazów?
W sumie w ustawieniach strony jest możliwość zmiany justowania, ale jeszcze w żadnym pliku nie mogłem tej opcji użyć ;)
I druga sprawa – jaka rozdzielczość i proporcja okładek będzie odpowiednia do tego, żeby wszystkie okładki wyglądały równo w układzie siatki?
Justowanie możesz zmieniać tylko w plikach KFX. W pozostałych formatach jest zdefiniowane w e-booku.
Wzorcowa okładka ma rozmiar 2700 × 1688. Proporcje najlepiej 4:3 (np. 2000 × 1500 będzie bardzo dobre) lub zbliżone do tych z rozmiaru wzorcowego.
Mam ciekawy przypadek z kilkoma książkami z http://english-e-books.net/ (wszystkimi które pobrałem).
Calibre wyliczyło identyfikator
mobi-asin:d455d4a7-01cd-4e3a-a4e8-b4aa8223bb97
i w /system/thumbnails/ jest odpowiadający mu plik okładki
thumbnail_d455d4a7-01cd-4e3a-a4e8-b4aa8223bb97_EBOK_portrait.jpg
ALE okładki nie widać tzn. nie widać na Grid książek w kolekcji (inne widać).
Ciekawostka: jeśli w Calibre przez wysłaniem do Kindle pobiorę inną okładkę (w edycji matadanych np. z google), to po przesłaniu do Kindle okładka jest widoczna.
Być może ma to jakiś związek z tym, że książki są z http://english-e-books.net/ a może tym, że te okładki są tylko 176×280 (te pobrane zwykle są większe).
Podmieniając okładki jw. obchodzę problem ale jest to uciążliwe.
Może ma ktoś pomysł co jest przyczyną i jak to rozwiązać?
Pozdrawiam,
Artr
Problem jest dokładnie z tym co podejrzewasz – zbyt małe obrazki.
Thx za wyjaśnienie.
Wiesz może od jakiej wielkości Kindle pokazuje okładki?
Jak rozumiem, by je widzieć na Kindle, to np. w Calibre powinienem usunąć mniejsze niż AxB i pobrać brakujące (o ile pamiętam jest opcja „pobierz brakujące okładki” i „usuń mniejsze niż AxB” ale chyba nie ma „pobierz brakujące okładki jeśli aktualna mniejsza niż AxB”)?
Nie mam pod ręką odpowiedniej tabelki. Wielkość zależy od docelowego czytnika. Dla Voyage (i PW3, Oasis itp.) wystarczy 620×440. Mniejsza może (aczkolwiek nie musi) być usuniętą. Nawet jeśli chmura ją zostawi, powstanie straszna pikselówka (chyba że to jednolite tło). Docelowo Amazon zaleca wielkość ok. 1500 px dla krótszej krawędzi. Na czytnik i tak trafi odpowiednio przeskalowana.
Według reguł Kindle Direct Publishing minimalny rozmiar okładki to 1000 x 625 px. Ale to jest plik, który trafia nie do ebooka, a w amazoński ekosystem publikacji książek i rozmiar może być ostatecznie zmniejszony.
To o czym piszesz pewnie nie jest wprost napisane na stronach Amazonu.
Oczywiście, że nie jest nigdzie wprost napisane. Wyłuskałem metodą prób i błędów. Zakładam że jak sprawdziłem 15 testowych plików i przeszły, a po zmniejszeniu o 1 px już nie, to dotarłem do granicy. Teraz już nie odtworzę tabelki, bo z czytników Amazona pozostał mi tylko Voyage.
A ustawienie okładki zgodnie z KDP skutkuje tym, że na czytniku zostaje biały pasek na dole (ok. 2 mm), co przy ciemnym tle okładki wygląda fatalnie. Tak więc całe KDP trzeba traktować jako luźne wskazówki, a nie sztywne wytyczne.
Dzień dobry!
Jestem świeżo upieczoną posiadaczką Kindla PW3 i mam mały problem. Przerobiłam kilka książek w Calibre, dodałam własne okładki, przekonwertowałam do AZW3 i przez program wysłałam wszystko do czytnika. Niestety dodane okładki nie są widoczne (a w zasadzie są przez pierwsze kilka sekund po wysunięciu urządzenia, a kiedy odpinam kabel wszystko znika). Czy ma Pan jakiś pomysł, co robię nie tak? Starałam się podążać za opisanymi w artykule radami, niestety nic nie pomaga.
Czy to aby nie jest mój przypadek i problem wynika z małej rozdzielczości okładki? Spróbuj może w Calibre podmienić/pobrać inną „dużą” okładkę (co najmniej 620×440) i przesłać ponownie – może to zadziała.
Przerabialem juz do azn3 i mobi po przeslaniu kablem usb przez explorera czy tez calibre okladka znika sekunde po wyjeciu kabla. Takze PW3
Wy oboje tak na serio? To jednostkowy przypadek, czy tak dzieje się przy każdej książce? Od jak dawna problem występuje?
Tak dzieje się przy każdej książce od czasu zakupu PW3 czyli jakies 2 tygodznie. Okladki ponad 1000px tez
Zacznij od przywrócenia ustawień fabrycznych. Wygląda to na paskudny glitch.
Witam
Jestem nowym właścicielem Kindla PW4 i mam podobny problem.
Calibre skonfigurowałem według wyżej podanego opisu.
E-booki konwertuje do AZW3 okładki zostawiam albo dodaje nowe i przesyłam za pomocą Calibre do Kindla.
Teoretycznie powinny się pojawić na czytniku, ale tak nie jest.
Za każdym razem pojawiają się one tylko na parę sekund na urządzeniu i znikają.
Jednak gdy usunę te okładki na Kindlu z katalogu /amazon-cover-bug/ okładka pojawia się na czytniku.
Czy ktoś zna odpowiedz dlaczego tak się własnie dzieje?
A może coś robię nie tak?
Czy powie mi ktoś, dlaczego w 1wszych opowiadaniach wiedźmina nie ma polskich znaków: ć,ł,ą,ę,ż,ś jest tylko ó. Da sie to jakoś przerobić?
Nie żartuj, nawet w próbce są poprawne polskie znaki…
Chyba że pobrałeś ze strony typu chomikuj, wtedy kontaktuj się z nimi, na pewno szybko poprawią i prześlą ci dobry plik.
Pliki .mobi mają swoje własne tagi, gdy wyślę je bezpośrednio do chmury amazonu, czasem mi nie odpowiadają (zamieniona kolejność imię-nazwisko, samo nazwisko autora, bądź same wielkie litery) jak zmienić te tagi, abym mógł je dowolnie edytować?
Edytowanie tytułu i autora w Calibre nic nie daje.
Zmiana metadanych w Calibre zmienia je tylko w bazie danych Calibre. Plik musisz jeszcze skonwertować do pożądanego formatu.
Czyli z poziomo Calibre nie da się tych metadanych zmienić, jakaś wtyczka, coś…
Java Mobi Metadata Editor? Tylko nie pamiętam, czy on będzie działał z nowym formatem mobi.
Tu masz specyfikację nagłówka, miłej zabawy :-)
Nie potrafię sobie poradzić z takim scenariuszem – książki, które samodzielnie przerabiam Calibre i wrzucam kablem na czytnik chcę mieć pełną kompatybilność z Goodreads, a zarazem własne dodane okładki. Na ten moment doszedłem, że aby Kindle znajdował książkę w Goodreads musi być poprawnie ustawiony ASIN oraz format AZW3. Zacząłem edytować i poprawiać w tę stronę i doszedłem do momentu, w którym mogę oznaczać statusy na Goodreads oraz przeglądać książkę, ale po podłączeniu do internetu okładki pobierają mi się z Amazonu na podstawie ASIN. Jest jakiś sposób, aby wymusić używanie okładki z pliku przy jednoczesnym poprawnie ustawionym ASIN?
Zauważyłem, że pojawił się u mnie problem z widocznością okładek na moim „archaicznym” Paperwhite II. Od zawsze robiłem to tak samo – książka do Calibre, ew. dodanie okładki, konwersja do AZW3, wtyczka Hyphenate This! i na koniec Quality Check -> Fix -> Fix ASIN for Kindle Fire i wgranie książki po kablu na czytnik – zawsze działało idealnie. I niestety teraz próbując wgrać jedną z książek, zauważyłem, że bezpośrednio po wgraniu i odłączeniu od kompa czytnika, jest okładka na wgranej książce, która dosłownie po 1-2 sekundach znika i widoczna jest domyślna z Kindle (nie ma tagu Personal). Dlaczego tak się dzieje?
Użyj Calibre 4.17.
Odłącz czytnik i podłącz go jeszcze raz przy włączonym Calibre.
Rzeczywiście miałem starszą wersję Calibre, zaktualizowałem, ale niestety nie pomogło. Dalej jest tak samo. Kasowałem książkę z Calibre, z czytnika, dodawałem na nowo i nic. Zauważyłem, że po wgraniu książki, w pamięci głównej czytnika tworzy się katalog „amazon-cover-bug”, w którym jest plik jpg z okładką tej właśnie książki o nazwie „thumbnail_….._EBOK_portrait”
U mnie na Kindel PW4 dzieje się tak samo. Zauważyłem jednak gdy wykasuje okładki z katalogu „amazon-cover-bug” … okładka pojawia się na czytniku
Może jeszcze raz:
1. wgrywamy książki przez Calibre na czytnik;
2. odłączamy czytnik od komputera;
3. obserwujemy znikające okładki;
4. ponownie podłączamy czytnik do komputera przy włączonym Calibre;
(tutaj dzieją się czary, musimy odczekać na przywrócenie okładek)
5. odłączamy czytnik od komputera;
6. okładki powinny być i nie powinny zniknąć.
Wielkie dzięki Ninka92 … wszystko działa jak należy … okładki wyswietlają się na czytniku :-)
Jaki profil źródłowy powinien być ustawiony dla PocketBook?
> …jeśli chcemy mieć idealny plik, trzeba go na czytnik wysyłać po kablu.
Nie, nie i jeszcze raz nie! Ani wtedy, ani dziś. Trochę się zmieniło w międzyczasie i przydałby się uaktualniony wpis na ten temat.
Był o tym nowszy artykuł: https://swiatczytnikow.pl/jak-przy-pomocy-calibre-poprawic-e-booki-wysylane-na-kindle/ ale i tak jest w tym momencie nieaktualny, skoro nie dostaniemy dzielenia wyrazów.
Widziałem. Chodzi mi o coś zgodnego z obecnymi realiami.
Mam pytanie odnośnie okładek na Kindle. Robiąc e-booki w Calibre mam ustawioną okładkę, po zapisaniu jako EPUB jest wszystko ładnie pięknie, okładka pokazuje się jako miniaturka na PocketBooku, natomiast na Kindle ta miniaturka się nie pojawia :( jak można ustawić miniaturkę okładki, żeby po wgraniu na czytnik Kindle była ona widoczna? Nie chodzi mi o podmianę okładki na czytniku w /system/thumbnails/, wgrywam plik MOBI na czytnik i pojawia się miniaturka, tak jak w przypadku PocketBooka. Podczas eksportu na MOBI mam zaznaczoną opcję „Użyj okładki z pliku źródłowego”.
Artykuł jest dość stary, w przypadku wysyłki epub przez Send To Kindle okładka powinna się pokazać prawie w każdym przypadku.
Dziękuję za szybką odpowiedź. Wgrywam MOBI przez kabel USB. Publikacje są udostępniane jako wersje darmowe, każdy może je pobrać. To co Pan proponuje, działa jeśli będę miał Kindle przy sobie. A mnie chodzi o to, by każda osoba która będzie miała plik MOBI i wgra go na czytnik, miała tą miniaturkę na swoim czytniku.
czy to może być ten problem?
https://manual.calibre-ebook.com/faq.html#covers-for-books-i-send-to-my-e-ink-kindle-show-up-momentarily-and-then-are-replaced-by-a-generic-cover
Czy po podłączeniu czytnika do komputera z uruchomionym Calibre i ponownym odłączeniu, okładki w bibliotece się pojawiają?
Najlepiej publikować książki w uniwersalnym formacie epub. Jeśli ktoś obstaje przy ręcznym wgrywaniu MOBI, to pewnie i tak używa Calibre i ten powinien okładki wgrywać (choć jest to zabugowane).