
Popularne słowniki dla Kindle będą teraz dostępne w formacie StarDict dzięki przydatnemu konwerterowi.
Stardict to międzynarodowy, otwarty format słowników, obsługiwany przez liczne aplikacje, jak KOReader, a także czytniki jak Onyx Boox.
Tymczasem najlepsza oferta słowników na polskim rynku to wciąż pliki dla Kindle. Przy czym „najlepsza” to zaledwie parę tytułów, ale cieszmy się tym co mamy.
No i tak:
- Wielki słownik angielsko-polski dostępny jest w wersji na Kindle w sklepie Ebookpoint, niedawno ukazała się aktualizacja. Jest też wersja dla PocketBooka, sprzedawana w Naffy, ale na tym koniec.
- Słownik Języka Polskiego ściągniemy bezpłatnie z serwisu Zabałaganione miejsce, jest tam również wersja dla PocketBook.
- Słowniki literackie dla Kindle: czeski i włoski, które ściągniemy ze strony sowaczyta.pl – kiedyś je omawiałem.
Niedawno napisał do mnie Grzegorz Czernatowicz, który korzysta obecnie z czytnika Onyx Boox, no i brakowało mu tych słowników. A że umie programować, to zrobił konwerter.
Szczegóły na stronie Github projektu, tam też znajdziemy samą aplikację.
Co ważne – aplikacja działa w przeglądarce, tak więc pliku słownika, chronionego przez prawo autorskie nigdzie nie wysyłamy. Kod aplikacji jest otwarty, jeśli chcemy możemy go przejrzeć i skopiować.
Jak skorzystać z konwertera?
Na stronie aplikacji znajdziemy dość dokładną instrukcję.
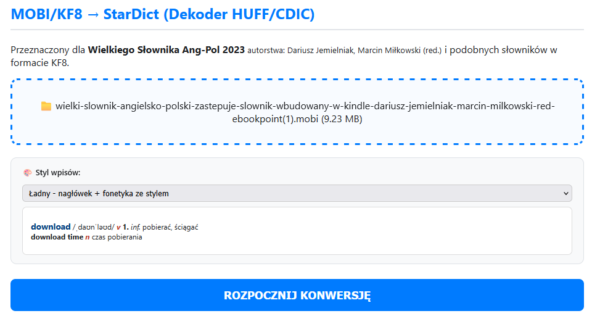
Najważniejsze jest to, że słowniki z rozszerzeniem „mobi” mogą być w dwóch formatach. Obecny WSAP oraz SJP są w nowszym formacie KF8. Jeśli mamy starszy plik WSAP (kiedyś kupiony w Amazonie) lub słowniki literackie – one mają starszy format MOBI.
Aktualizacja: od wersji v2 (czerwiec 2026) konwerter sam rozpoznaje format pliku.
Ładujemy plik i wybieramy styl wpisów ze słownika.
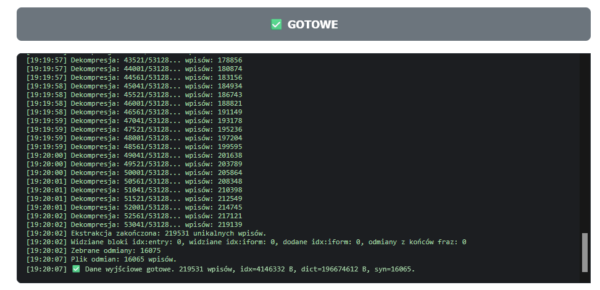
Zaczynamy konwersję, a w okienku widzimy szczegółowe podsumowanie.
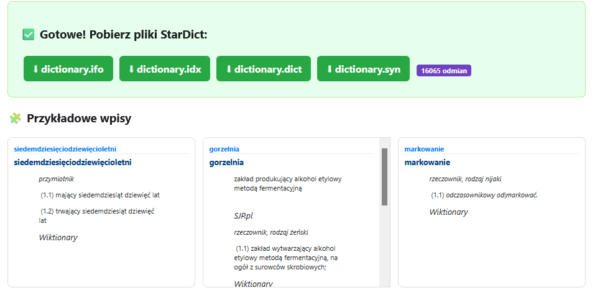
Po wygenerowaniu pobieramy cztery pliki słownika, a także możemy podejrzeć przykładowe wpisy.
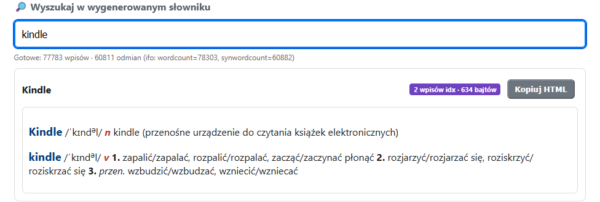
Możemy też gotowy słownik przeszukać.
Warte uwagi są dodatkowe narzędzia:
- Tester wersji sprawdza w jakiej wersji formatu MOBI jest nasz słownik – nowszej czy starszej
- Przeglądarki słowników w formacie MOBI
- Walidator StarDict pozwala wczytać i sprawdzić istniejący słownik
Widać, że narzędzie jest bardzo dopracowane – nawet za bardzo, jak na służące do jednorazowego użycia, ale kto wie, jakie słowniki nam się trafią.
Uwaga: ponieważ konwersja ma miejsce w przeglądarce, możliwe, że jeśli mamy słabszy komputer lub korzystamy z urządzenia mobilnego, może nam się coś przyciąć.
Jak zainstalować słownik Stardict na Onyx Boox?
Jeśli mamy czytnik Onyx Boox, warto napisać, jak zainstalować taki słownik na czytniku, bo nie musi być to oczywiste:
- Ściągamy cztery wygenerowane pliki
- Podłączamy czytnik do komputera i w pamięci wewnętrznej znajdujemy folder „dicts”. Jeśli by go nie było, to go tworzymy.
- Na potrzeby nowego słownika tworzymy nowy folder, np. „SJP”, który będzie też jego nazwą.
- Do folderu przegrywamy pliki.
Po wgraniu słownika trzeba go jeszcze aktywować w ustawieniach.

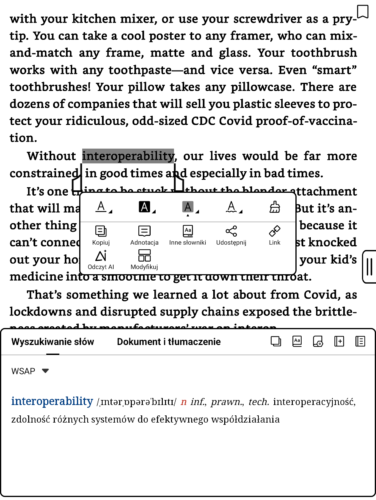
No i można już użyć słownika w książkach. Tu w „The Internet Con” Cory’ego Doctorowa.
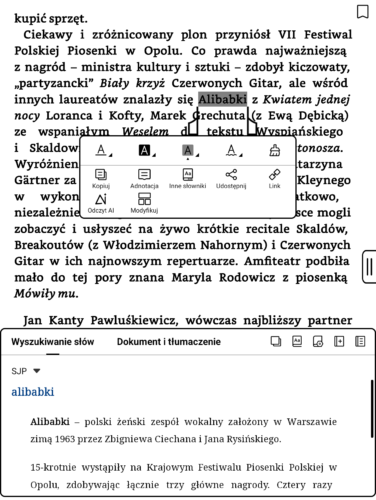
A tu Słownik Języka Polskiego połączony z Wikipedią w polskiej książce o Beatlesach.
Zauważyłem jednak, że słownik języka polskiego przerobiony na Stardict nie obsługuje odmian słów. Nie wiem czy da się tak ten słownik poprawić (chyba trzeba by zwiększyć liczbę synonimów w pliku .idx).
Podsumowanie
Bardzo mnie cieszą takie inicjatywy. Zamiast czekać na to, aż wydawca słownika opublikuje nowy format, przygotowany zostaje konwerter. Co ważne – do jego użycia nie trzeba jakiejś zaawansowanej wiedzy.
Bo od dawna istnieją już inne, które umożliwiają konwersję formatów słowników, np. mobi2stardict, albo chyba najbardziej uniwersalny PyGlossary. Wymagają one jednak instalacji, a tu mamy po prostu aplikację działającą w przeglądarce.
Jeśli więc korzystacie z formatu StarDict dajcie znać, jak Wam poszła konwersja i czy słowniki działają prawidłowo.
Aktualizacja z 10 czerwca 2026: parę dni temu pojawiła się nowa wersja, która rozpoznaje automatycznie format pliku ze słownikiem (nie trzeba sprawdzać), a także wykrywa więcej odmian i ma lepszą kompresję. Poprawiony też został błąd w konwersji SJP, o którym pisaliście w komentarzach.


{kind=link}
Poza tematem: ale właśnie Nexto napisało, że zamyka się w kwestii ebooków i audiobooków. Zostawiają tylko prasę.
Robert już działa z tematem ;)
Tak, dowiedziałem się o tym minutę od publikacji tego posta i stwierdziłem, że już nie będę wycofywał. O Nexto napiszę dzisiaj.
Czy ta konwersja zadziała dla słowników kupionych w Amazon?
Sądzę, że tak, o ile uda się zdjąć z nich zabezpieczenia DRM.
WSAP śmignął ale SJP wywala błąd. Ale dziękuję za narzędzie, nareszcie ogarnęłam porządny słownik na Palme.
[00:15:17] Ekstrakcja zakończona: 219531 unikalnych wpisów.
[00:15:17] Widziane bloki idx:entry: 0, widziane idx:iform: 0, dodane idx:iform: 0, odmiany z końców fraz: 0
[00:15:17] Zebrane odmiany: 16075
[00:15:44] BŁĄD KRYTYCZNY: Invalid array length
RangeError: Invalid array length
at Array.push ()
at renderOutput (https://random90.github.io/mobiDictToStarDictConverter/mobiKF8HuffConverter.html:1879:36)
at https://random90.github.io/mobiDictToStarDictConverter/mobiKF8HuffConverter.html:2054:15
A który plik SJP konwertowałaś? Ja wczoraj na potrzeby artykułu skonwertowałem SJP2-202507140955.mobi, no i poszło.
Plik SJP2-202507140955, świeżo ściągniety.
Konwertowałem SJP 202507140955.mobi i też wywala ten błąd
Jestem autorem konwertera. Jak tylko wrócę z urlopu w przyszłym tygodniu i odzyskam dostęp do komputera, to znajdę błąd i go poprawię. W repozytorium na github już ktoś też wysłał zgłoszenie.
Panie autorze, super narzędzie, przerobiłem WSAP i wszystko poszło elegancko.
Chciałem przerobić to dalej na format Kobo, ale chyba nie ogarnę, może w przyszłości zrobiłby Pan kolejny konwerter?
A póki co chyba wgram NickelMenu, Koreadera i będę tam używał stardictowego.
Potwierdzam błąd dla SJP – wyrzuca tym konwerterem do nowszych plików. Natomiast, ten sam słownik przekonwertowany przez ten dla starszych, tworzy 3 pliki wyjściowe zamiast 4 (i czytnik w książce go nie widzi).
Słownik ang-pol działa bez zarzutu.
W ogóle super pomysł z tą konwersją. Takich słowników mi brakowało na Onyxie, bo na Kindlu się dobrze sprawdzają.
Wielki ukłon dla autora.
To ja może do powrotu Autora wrzucę link do mojej kopii, która się przekonwertowała prawidłowo i działała na Onyx Go 7 Color:
https://swiatczytnikow.pl/downloads/sjp.zip
(EDIT: zawartość linku poprawiona na ten słownik jaki mi działał)
Dzięki Robert. Czy Tobie ten słownik normalnie chodzi? Bo u mnie po naciśnięciu słowa pojawia się puste okienko. Ten plik wg mnie jest podejrzanie mały. Słownik angielski ma 9,33 MB (mobi), a *dict po przekonwertowaniu ma 25,6 MB. Natomiast SJP odpowiednio: 33,3 MB (mobi) i 1,44 MB (dict). Dziwne, że po przekonwertowaniu ma mniej MB.
Pobierz jeszcze raz. Nie wiem co ja tam wrzuciłem, ale to na pewno nie słownik, jaki mam na czytniku. Przegrałem teraz bezpośrednio z czytnika i .dict ma 190 MB :)
Dziękuję. Teraz działa (w tej okrojonej wersji bez odmiany), ale to i tak dużo lepiej niż brak słownika :)
Wypuściłem nową wersję. Błąd poprawiony i dodałem mnóstwo nowych ficzerów, w tym lepsze wykrywania odmian, których do SJP dodaje się 2.5 miliona :) dodałem też m.in kompresję, więc słownik już nie ma ponad 220 MB, tylko bliżej 50-60.
A czy ktoś może podpowiedzić, czy/gdzie mogę przekonwertować słownik dla Kobo? Mam „Wielki słownik angielsko-polski” z ebookpoint i bardzo mi on odpowiada, gdy korzystam z Kindle’a. Na Kobo oczywiście nie działa, więc ściągnięty mam słownik z mobileread, który nie jest aż tak dobry.
Zdaje się, że na Kobo można też wgrywać słowniki w formacie stardict – opisywał to kiedyś Cyfranek: https://cyfranek.wordpress.com/2024/02/03/wikislownik-angielsko-polski-dla-kobo/
EDIT: a jednak nie. Kobo obsługuje formaty „dicthtml-*.zip” – trzeba gotowy słownik StarDict przekonwertować np. przy pomocy Penelope albo PyGlossary.
Ok. Sprawdzę i potestuję. Jeszcze nie robiłem nigdy konwersji słowników tymi narzędziami, a i Kobo używam od trzech tygodni dopiero. :)
Słowniki dicthtml wgrałem z mobile read właśnie na podstawie artykułu Cyfranka i jeden z nich (od Owl_ – 6.83 MB) jest całkiem niezły, tylko strasznie nieczytelny (wszystko ciągiem, bez wyróżnień, pogrubień, odstępów).
Dokładnie o tym samym pomyślałem, sprawdzę jutro na spokojnie czy uda mi się przerobić to mobi->stardict i czy potem w ogóle ogarnę tego pythona ;D
Udało się przygotować wersją WSAP na Kobo ze Stradict przy pomocy PyGlossary. Dziękuję za konwerter online i wszystkie porady!
Potwierdzam. Z PyGlossary się udało. W outpucie dla pliku dajemy rozszerzenie .zip, a format Kobo E-reader Dictionary.
„Obecny WSAP oraz SJP są w nowszym formacie KF8.”
Poważnie? Jak niby to jest format KF8, jak ten format nie ma indeksu słownikowego, niezbędnego do działania słownika. Na Kindle działają tylko słowniki w formatach MOBI 6/7 i KFX.
Pobrałem przed chwilą ten SJP i ma on ewidentnie format MOBI 7:
SJP2-202507140955.mobi: Mobipocket E-book „Creative Commons SJP (2025-07-16)”, 216129897 bytes uncompressed, version 7, codepage 65001
No to pytanie raczej do autora.
Może warto sprawdzić tester wersji: https://random90.github.io/mobiDictToStarDictConverter/Tools/versionTester.html (szczególnie jego kod), co on tam tak właściwie sprawdza.
Pewnie chodzi o kompresję Huffdic, a nie o format MOBI. Słowniki są najczęściej w rewizji 6, oznaczanej przez kindlegen jako 7.
Dokładnie chodzi o rodzaj kompresji tylko, a nie sam format. W testerze jest rozróżnienie. Niektóre te rzeczy napisałem na szybko zanim mniej więcej ogarnąłem co jest czym.
Przydałoby się poprawić to słownictwo i najlepiej połączyć osobne konwertery do jednego, ale wyszedłem z założenia, że jak zadziałało, to wystarczy jak jest.