
Niedawna aktualizacja programu Calibre do wersji 5.0 przyniosła trochę problemów, z którymi powoli sobie radzimy.
Jak pamiętamy, program został przepisany w 3 wersji Pythona, a to spowodowało konieczność zaktualizowania wszystkich wtyczek. Przez jakiś czas np. nie mieliśmy dostępnej wtyczki Hyphenate This!, odpowiadającej za dzielenie wyrazów w plikach EPUB/AZW3.
Działanie tej wtyczki opisywałem tutaj dwukrotnie:
- Jak podzielić wyrazy w e-bookach KF8 lub EPUB? (rok 2013)
- Jak przy pomocy Calibre poprawić e-booki wysyłane na Kindle? (rok 2015)
Wtyczka została zaktualizowana, ale zauważyłem, że czasami dzieli wyrazy… dość dziwnie.
Problem
Oto przykład z książki Euro. W jaki sposób wspólna waluta zagraża przyszłości Europy autorstwa Josepha Stiglitza.

Przy niektórych słowach polskie znaki znajdują się nieprawidłowo w następnym wierszu.
Np. rozwi-ązaniami, albo zamkni-ętymi.
Co się stało?
Wtyczka Hyphenate This! korzysta z dostępnego publicznie pliku słownika hyph_pl_PL.dic, który ma wiele lat i stosowany jest choćby w programie Libre Office. Nawet ustawienia wtyczki odsyłają do Libre Office.
Co więcej, z identycznego pliku korzysta program Calibre, który w ramach funkcji „Dopracuj książkę” ma również dodawanie łączników opcjonalnych – jako „Add soft hyphens”.
No i podział przez „Dopracuj książkę” działał, przez wtyczkę już nie.
Pierwszy jest taki, że wtyczka daje dodatkowe możliwości – np. pominięcie nagłówków i krótkich wyrazów.
Drugi, że „Dopracuj książkę” działa co najmniej dziwne – jeśli poprawimy w ten sposób plik EPUB, to przy konwersji do MOBI program z niego… nie korzysta, a bierze niezmodyfikowaną kopię oryginału, oznaczoną jako „ORIGINAL EPUB”. Uznałem że to błąd, zgłosiłem w bugtrackerze Calibre, na co odpowiedział mi sam Kovid Goyal, twórca Calibre, że tak ma być. No cóż, niezbadane są ścieżki myślenia developerów.
Jeśli uprzemy się przy korzystaniu z „Dopracuj książkę”, w zaawansowanych ustawieniach Calibre można tworzenie kopii wyłączyć – ustawiamy następujący parametr:
save_original_format_when_polishing = False
Dobre i to.
Rozwiązanie
Na rozwiązanie wpadł nasz czytelnik Dariusz.
Okazuje się, że plik hyph_pl_PL.dic korzystał ze starego kodowania znaków, popularnego w swoim czasie w internecie ISO 8859-2. Obecnie większość stron, ale również e-booków zapisywana jest w formacie UTF-8.
I wystarczyło przekodować plik słownika do UTF-8. Tu możecie go pobrać. Jeśli otwiera się zamiast zapisywania, skorzystajcie z opcji „zapisz link jako…” lub podobnej pod prawym klawiszem myszki. Ewentualnie link do pliku ZIP.
Sprawdziłem na paru książkach i już jest w porządku. Wracamy do Stiglitza.

Plik instalujemy tak jak opisywałem we wcześniejszych artykułach. Z menu wtyczki Hyphenate This (będzie dostępna w głównym pasku Calibre jako „Dziel wyrazy”) wybieramy „Settings”.
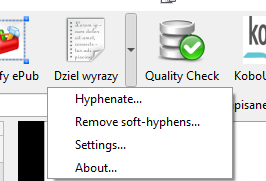
Następnie dodajemy z dysku plik słownika („hyph_pl_PL.dic”). Jest to czynność jednorazowa. Potem możemy już przerabiać pliki EPUB lub AZW3.
Jeśli mieliście podobnie jak ja problemy z podziałami wyrazów, sprawdźcie nowy plik słownika.
PS. Jeśli ktoś wysyła przekonwertowane w Calibre pliki na Kindle w formacie MOBI „both” (patrz artykuł 50 twarzy MOBI), może zauważyć, że ostatnio część plików konwertuje się nieprawidłowo. Napiszę o tym niedługo artykuł, tymczasem wspomnę tylko, że konieczne jest tutaj użycie konwersji przy pomocy amazonowego programu Kindle Previewer.


{kind=link}
Ja po prostu nie aktualizuję calibre bo i po co skoro działa
No, biorąc pod uwagę te problemy, żałowałem że nie zostałem przy wersji 4.x. Ale problem z PS. występuje też przy 4.23, którą w desperacji zainstalowałem, więc pozostanie nie rozwiązuje wszystkiego.
Zaletą Calibre 5 jest jednak znacznie większa szybkość, np. konwersji, ale również wyszukiwarki. Jak w starym wpisałem w wyszukiwarce tytuł książki, międlił i międlił dysk przez kilkanaście sekund nawet. W nowym działa to natychmiast (co nie jest pewnie zaletą pythona tylko nowego formatu bazy danych, może wreszcie indeks dodali).
Ja mam 4.21 i nigdy nie miałem problemów z mielącą wyszukiwarką, ułamek sekundy i są wyniki.
A ile masz książek w Calibre? Ja 3870.
4x mniej ale to i tak chyba całkiem sporo xd
U mnie jest ponad 5000 pozycji i też zero problemów z wydajnością wyszukiwarki, zarówno w wersji 5.x jak i 4.x.
Ja od jakiegoś czasu zamiast Hyphenate This! używam epubQTools, jest nawet nowsza wersja przekonwertowana na pythona3 – https://github.com/johnykvsky/epubQTools ostatnio na nią trafiłem, sprawdzałem i działa, chociaż nie jest to oficjalne wydanie (program jest już nierozwijany?)
Plik po konwersji wygląda lepiej niż po Hyphenate – tak to ustawiłem, że mam skrypt, który wszystkie pliki w danym katalogu konwertuje, jak kupuję książkę, to zapisuję do niego, odpalam skrypt, mieli, jak gotowe, to dodaję do calibre epub i mobi.
Dzięki, muszę potestować jak to działa pod windows. Faktycznie sądziłem, że program nie jest już rozwijany.
I z tego co pamiętam epubQTools tworzył plik mobi z podziałem wyrazów (!).
„Następnie dodajemy z dysku wtyczkę.” – chyba chodzi o słownik?
Tak, moja pomyłka. Już poprawione.
Ktoś mógłby mi wyjaśnić jak pobrać ten przekodowany słownik z podanego linku w artykule? Moja przeglądarka go wyświetla zamiast pobrać (Opera i Egde).
Prawy przycisk myszy i „Zapisz link jako”
Podaję też link do pliku zip:
https://swiatczytnikow.pl/downloads/hyph_pl_pl.zip
To nie może być takie pros…
…
…
…
A jednak 🤣
No nie wiem, czy jest dobrze po przekonwertowaniu do utf-8? Po podmianie słownika w czytniku nadal występują kwiatki typu: stoj – ący.
Upewniłbym się czy na czytniku nie masz starej wersji książki. No i przed ponownym podzieleniem trzeba usunać podziały (remove soft hyphens), a także jeśli trzeba, przekonwertować z epub do mobi.
Już to robiłem. Podział przy pomocy wtyczki i słownika w utf-8, zamiana słowników w czytniku, usunięcie słownika z czytnika. Wynik za każdym razem do d… Przypuszczam, że jest to konflikt wtyczka – opcja w dopracuj książkę. Zadałem sobie trud odszukania w słowniku błędnie podzielonego słowa i w słowniku był zakaz dzielenia w tym miejscu (o zakazie lub możliwości dzielenia decyduje parzysta lub nieparzysta cyfra). W chwili obecnej używam „dopracuj książkę” , słownik wywalam z czytnika, w css ustawiam blokadę podziału nagłóków.
Ja mam taki problem, że po wrzuceniu na mojego Kindle’a przekonwertowanego pliku AW3, po operacji dzielenia wyrazów, słowa są niewyszukiwalne na urządzeniu – Kindle ich po prostu nie widzi w wyszukiwarce. Jedyny sposób to zaznaczenie jakiegoś wyrazu i kliknięcie lupki, żeby znaleźć pozostałe takie same wyrazy w książce czy na urządzeniu.
Czy jest na to jakieś rozwiązanie?
To wina oprogramowania kindla i nie tylko kindla. Gdy wstawiasz podział słów wstawiasz „znaczniki”, które są niewidoczne na ekranie, ale wyszukiwanie ich nie ignoruje.
Znowu nie działa podział wyrazów. Myślałem, że starą konfigurację wgrałem. Usunąłem słownik, katalog. Wgrałem wskazany słownik i nadal dzieli „mi-ędzy”. Calibre „Dopracuj książki” działa poprawnie.