

Brak pamięci? Nie, raczej kolejny irytujący błąd oprogramowania Kindle.
Dziś po południu na moim Kindle Scribe pierwszej generacji pojawił się dość nieoczekiwany błąd.
Storage full
Your Kindle is out of storage. To continue downloading items
or saving highlights, notes and bookmarks, remove content
from your Library or go to Settings > Storage management.(poniżej tłumaczenie)
Pamięć jest pełna
W Twoim Kindle’u zabrakło pamięci. Aby kontynuować pobieranie elementów lub zapisywanie zaznaczeń, notatek i zakładek, usuń zawartość z Biblioteki lub przejdź do Ustawienia > Zarządzanie pamięcią.
No dobrze, ale przechodzę do funkcji Storage Management i widzę, że mam jeszcze 10,8 GB!
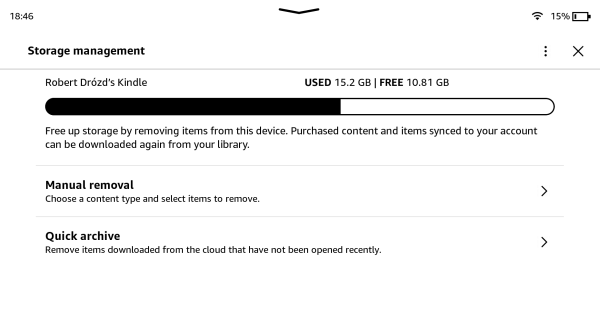
Po co mam więc coś usuwać?
Komunikat komunikatem, ale zauważyłem, że faktycznie nie mogę dodawać podkreśleń oraz zakładek. Po próbie zaznaczenia tekstu wyświetla się ponownie ten komunikat, a podkreślenie nie zostaje zapisane.
No dobrze, usunąłem coś, ale komunikat jest nadal. Zresztą bez problemu ściągnąłem kilkanaście kolejnych książek z chmury. Problem dotyczy więc prawdopodobnie zapisywania jakichś danych związanych z konkretną książką (podkreślenia, zakładki, informacje o miejscu w którym jesteśmy), a nie braku pamięci na samym urządzeniu.
Widzę, że problem pojawił się dzisiaj po południu – są już wątki na Mobileread, Amazon Forum albo Reddicie. Wygląda na to, że dotyczą wszystkich czytników z wersją 5.19.2, która weszła ponad tydzień temu. Ale skoro komunikat wyskakuje dopiero dzisiaj – zapewne Amazon zrobił znowu jakąś „cichą” zdalną aktualizację.
Na Amazon Forum pojawiła się wypowiedź osoby z Amazonu, która potwierdza, że wiedzą i naprawiają. Jest to wszystko jednak bardzo frustrujące. Czy producent Kindle robi w ogóle jakieś testy? Czy też puszcza aktualizacje na żywioł i niech miliony czytelników się wkurzają.
I ankieta.
Aktualizacja z 27 lutego: błąd podobno został już naprawiony, przynajmniej u siebie go nie widzę. Jeśli nadal na niego trafiacie, zróbcie restart czytnika.


{kind=link}
Nie tylko to, u mnie na przykład nie wyświetla się prawidłowo czcionka Bookerly. Jest tylko jakiś pionowy ciąg znaków. Bardzo żałuję, że zaktualizowałam (Kindle Colorsoft).
Ja już dawno odpuściłem sobie aktualizowanie ręczne Kindli. Niech inni robią za testerów ;)
Czyli w zespole Kindle Amazona dzień jak co dzień. Wprowadzamy nowe funkcjonalności psując przy tym inne rzeczy. Kontroli jakości i działku testów to tam chyba nie ma w ogóle…
Gwarantuję, że można mieć w firmie wszystko to, o czym piszesz… a bugi w kodzie i tak zawsze będą się pojawiać. I piszę to jako doświadczony deweloper pracujący w zespole składającym się z 7 devów i trzech inżynierów jakości (jednym w wielu w firmie). My piszemy swoje testy, oni swoje, testy wykonywane są ręcznie i automatycznie… a bugi jak były tak są :P
Też pracuję jako dev od 8 lat komercyjnie, więc wiem o czym piszesz, natomiast z Kindle’a korzysta wiele, wiele osób, szczególnie w USA – to nie jest takie kodowanie, jak koduje większość z nas – aplikacje czy inne strony webowe. Powinno to przechodzić przez testy długi, długi czas i nie w sandboxie tylko w realnym użyciu.
Uwaga moja miała uwzględniać to, że w urządzeniach Kindle dzieje się to nagminnie przy wielu aktualizacjach. Coś dodają, zaraz usuwają, cos jednego dnia widać, drugiego już nie. Jest to bardzo niejawne, niejasne, niespójne. Jest bajzel i tyle.
Gwarantuję, że da się to robić lepiej.
No właśnie też nie rozumiem, dlaczego takie „incrementalne” aktualizowanie poza standardowym cyklem wersji Amazon uznał za potrzebne. Jasne, jak są funkcje działające online, to trzeba pewnie mieć możliwość szybkiego poprawienia działania, ale nie powinno to dotyczyć nowych funkcji.
Zdecydowanie ma to sens. Takie wrzucanie wszystkich zmian naraz w jednym wielkim pakiecie to jeden wielki koszmar z punktu widzenia tych, którzy tworzą te zmiany. A dzielenie tego pozwala na szybsze wychwytywanie potencjalnych problemów i reagowanie na nie. Przy milionach użytkowników to robi ogromną różnicę.
Pytanie z jakiego typu softem pracujesz. Bo ja pracuję z czymś z nieco innej działki, ale podobnym o tyle, że dotyczy użytkowania treści dostarczanych przez firmy trzecie. I wtedy, choćby się człowiek … (wiadomo co ;)), to wszystkich możliwych scenariuszy użycia nie przewidzisz i nie przetestujesz. Można teoretycznie spróbować to zrobić, ale jak „business” zobaczyłby koszty z tym związane (a, że wystrzeliłyby szybko pod sufit to pewne), to takie próby skończyłyby się szybciej niż zaczęły. :D
Więc, teoretycznie, dać się da. Problem polega na tym, że koszty w takim wypadku rosną o wiele zbyt szybko w stosunku do potencjalnych korzyści.
To jest Amazon i urządzenia kosztujące grube setki dolarów. Bez przesady, że tu trzeba koszty ścinać… mają wystarczające zaplecze finansowe jako cała spółka. Mają monopol, bo weszli na rynek dawno temu i miliony starych dziadów siedzi na starym, bo nie chcą, nie wiedzą lub nie potrafią się przenieść na nic innego. Dodatkowo Kindle wygrywa usługami powiązanymi z czytnikami. Oczywiście nie w Polsce, bo Polskę mają generalnie tam, gdzie właśnie testy jakości.
Po prostu procesy są skopane wdrażania i developmentu. Ktoś kładzie lagę na jakość i jest jak jest. Osobiście dawno już porzuciłem te niewarte swojej ceny kawałki układów scalonych.
A może to po prostu wzmożone użycie AI do kodowania, do czego pewnie mają ochotę w sytuacji rosnącego długu technologicznego i wielu wymagań dotyczących kompatybilności wstecznej.
Aha, dziś rano błąd już nie występuje, chyba go naprawili.
AI to nie kwestia „ochoty”. O ile koszty AI nie zabijają sensowności jego użycia w danym zastosowaniu, to ten kto nie będzie go używał za chwilę zostanie daleko w tyle za używającą go konkurencją.
A odnośnie błędu.. równie dobrze to mogła być kwestia jakichś testów. Skoro wyskakiwał błąd to pewnie mieli zalew raportów o nim i to wyłączyli.